3.1 Aspects of visXcerpt
After having provided a summary about querying XML data and various visual languages and systems, a new visual query system is proposed here. The semantics of the proposed system will be based on Xcerpt's semantics. Studying the related work shows that a lot of visual query systems are based on pattern matching. Pattern matching and unification in turn is a paradigm best explored in the logic programming environment. Nevertheless the most important query systems for XML (XSLT and XQuery) do not follow the logic programming paradigm. Further in-depth analysis of logical XML query systems would be interesting.
In the past visual query systems like QBE [zloof77query] have always been presented by their syntax as well as their semantic. However, QBE was proposed at a time before logic-based query systems were well analysed. Today the situation is different: A lot of work has been done in the analysis of underlying theories of logical query and programming languages. Xcerpt uses advanced techniques like constraint solving based on simulation unification, which provide a high potential of optimiseability like magic set strategy, tabelling and memorisation. For a visual XML query system based on pattern matching it therefore seems sensible to rely on the semantics of a well designed textual query language with the desired features, in this case Xcerpt. Thus the semantic of visXcerpt is equal to Xcerpt's semantic.
The remaining task to solve is to visually support Xcerpt. This will be accomplished by providing a new visual syntax. The guidelines therefore are (they will be explained in detail afterwards):
- support the comprehension of pattern structures, queried data
structures and generated results. This implies
- visually reflecting the generic nature of XML;
- visually distinguishing Xcerpt related visual components from XML related ones;
- supporting the process of editing query programs. Thus
- well known editing primitives should be used;
- editing steps should (as far as possible) lead from one valid query program to another, not confronting the user with syntactically incorrect programs;
- the user should be able to learn the language by exploration of the visual editors user interface, rather than being forced to skim a language reference manual;
- providing support to focus or to hide information without modifying the program.
The visXcerpt proposal is divided in two parts: The static aspects and the dynamic ones. The static aspects will cover the visual representation of Xcerpt programs as well as the visualisation of XML in general. The dynamic aspect of visXcerpt is the editor model through which the editing process is defined.
3.1.1 Static Aspects of visXcerpt
This section will describe all editing independent aspects of visXcerpt. They represent a visualisation of Xcerpt. Static does not mean that there is no user interaction covered by these aspects. Information hiding for example is a static aspect where user interaction may be used to hide or display parts of a document. It is categorised as static, because no information is altered that way. The static aspects are divided in two sections, one covering generic XML visualisation, another for visualising Xcerpt specific constructs. The focus on a generic XML visualisation is done, because the pattern mechanism of Xcerpt is in fact nothing else than providing sample XML documents or sample document fragments. Hence it is quite natural for patterns to be represented by something being usable for the representation of XML data. The same generic visualisation may be used to represent the query result, or it may be used to show XML documents.
3.1.1.1 visXcerpt's Generic XML Visualisation
Database terms are represented in visXcerpt through nested rectangular boxes with attached "tabs". This reminds of tabs used in graphical user interface toolkits, which supports the awareness of an underlying hierarchical structure. The child-elements visualisations are nested inside of the box. Because visXcerpt is primarily intended to be used with XML, there is special handling of textual content (so called CDATA), attributes and namespaces: Attributes are placed in a two-column table with the name in the left column and the value in the right one. The attribute table is the first content of the box. If there are no attributes, the table is omitted. Sub-terms (i.e. child nodes), are recursively visualised the same way and arranged vertically inside of the parent element's box. Textual content is simply written as plain text. In visXcerpt the namespace of an element is written on the top right corner in a smaller font and attribute namespaces are prefixed (also in smaller font) before the attribute name inside it's table cell. The width of an element box is at least the width used to represent the content, but it tries to use all width provided by the parent element. An element box is as long as needed to contain its content.
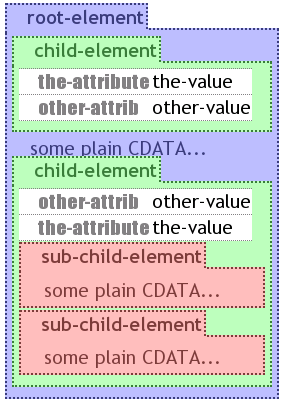
Opposed to many other visual languages, this way the position and the size of all elements (except the root element's size) is determined recursively through their parent's extends and locations. An advantage of this approach is that it is not necessary to keep visual meta information along with the XML document to reproduce the same visual arrangement. On the other hand the freedom of being able to re-arrange or re-size elements in an interesting didactic way for documentation purpose is lost.
For better recognition of the element depth, every level has a different background colour. The amount of colours may be restricted and they may be reused for deeper levels. For a pleasant look and feel not too many colours should be used. It turned out that three to six colours provide a good tradeoff between tree level recognition and economic colour use. It turned out to be pleasant to use light pastel colours for the background and the same colour in a much darker tone for the foreground.
A further way to support the metaphor of nested content is to use a lightly bevelled border line instead of a plain one and to introduce some kind of visual depth (The use of the prototype showed, that this feature is only useful for screen presentation and not pleasant on printed versions of the visualisation)
The XML visualisation as proposed by now is partly inspired by Martin Erwig's document metaphor [erwig-xml2000]. The document metaphor in turn is inspired from forms. Forms are known by most people e.g. as ordering forms or as forms for income taxes. Forms usually have in common that associated information is grouped in a boxed way, sometimes even using borders to show grouping.
Visualisation of large documents tend to get very long while not being too wide. For browsing of large documents, scrolling through the visualisation can be cumbersome. An information hiding mechanism is introduced to hide irrelevant parts of a document. Nodes can be folded by clicking on their tab. The content is hidden while light and dark shading of colours used in the tab are reversed. The labels are then displayed like tabs on registers along with other folded sibling elements, an unfolded element's label is the last one in the row of labels. If the amount of folded labels exceeds the width of the visXcerpt display area, a line-break occurs and a new line begins. For big databases all nodes can be folded in the initial state. The user can then dig into relevant areas by iteratively unfolding relevant nodes.
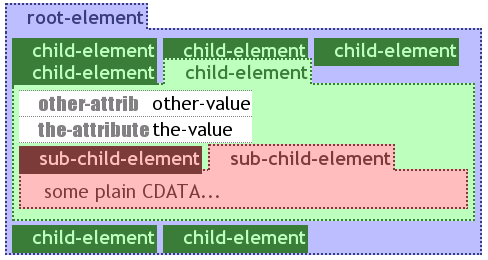
It is noticeable that a certain kind of order in the two dimensional visualisation was used for the former proposal: from left to right, then from top to bottom. This is based on the occidental textual document order for two dimensional information. In other cultures this order may be adapted to another order, e.g. in the visualisation of an arabic XML document, element names may be aligned to the right and flow to the left.
3.1.1.2 visXcerpt and graph structures
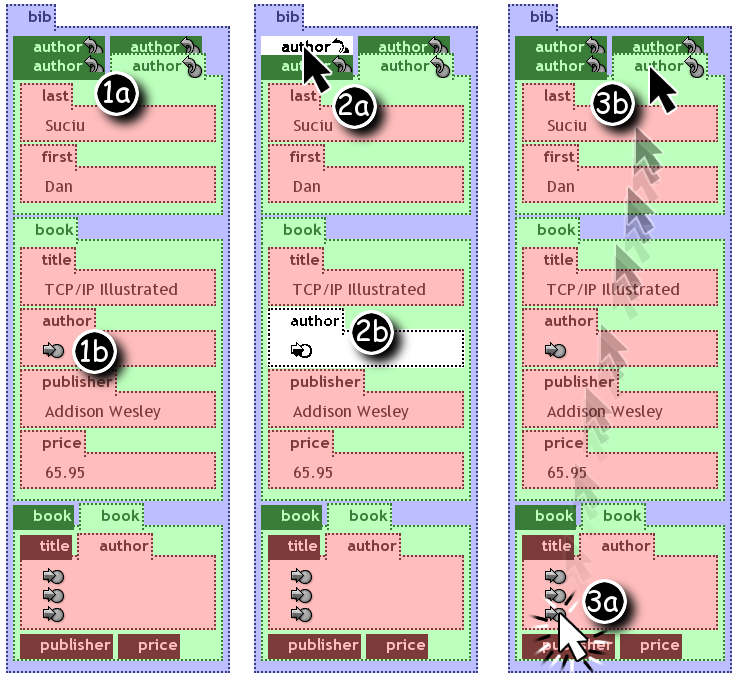
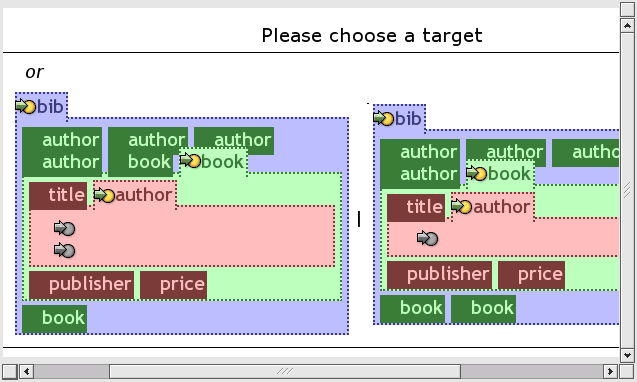
XML allows the construction of graphs using reference mechanisms. Graph representation is not fully implemented in visXcerpt, its development is still in progress. The solution retained for visXcerpt is the use of hyperlinks to cope with graph structure. The graph is represented by a spanning tree and references used to complete the graph are spanned in the "hyperspace". This departs from the approaches taken in most other visual languages, which are using two dimensional representations of nodes and edges for graph visualisation. While a two dimensional visualisation of non-tree graphs is suitable for small graphs, a hyperlink representation scales very well to graphs of arbitrary sizes. A reference is visualised as link (see 1b in figure bibWithRefs) to the referenced element (1a in figure bibWithRefs). Clicking such a link (see 3a) scrolls the user's visual context to the referenced element (3b). Furthermore, when hovering with the mouse pointer over a referenced element (see 2a), all referring elements are highlighted (2b). While browsing or editing documents using visXcerpt, it is also possible to navigate back to the referencing element via a back referring link.
A back referring link is comparable to web-browser's "back"-button, but it is not useful, while trying to find any element referencing to an element. For this purpose, a dialog that shows all instances referencing to an element can be used. The dialog must be accessible dependant of the referenced element. The context menu, described later in the section about the dynamic aspects, would be a good place for accessing the dialog. As seen in figure backRefDialog, it displays a disjunction of elements. Each element is the whole document with maximum possible information hiding, so that the referring element is still visible. Beside the element names, a hyperlinks that scrolls the main visual representation (not the dialog's visualisation) to the corresponding position is available. Displaying the whole document for each occurence of a reference is useful to better grasp the context of the referencing element.
While this specification is quite usable for generic XML visualisation, it may also be interesting to provide an extension mechanism for the visualisation of special elements or attributes, a kind of stylesheet for special applications. Presuming such a mechanism, the visualisation of the special Xcerpt components is proposed now.
3.1.1.3 visXcerpt Elements
The recursive nature of the former proposal for generic XML specification suggests to inherit the layout behaviour for the visual Xcerpt components. Nevertheless, direct children of Xcerpt components may be layed out in a different way. The liberal use of colours for generic visualisation suggests the use of a fixed colour scheme for Xcerpt components that is disjunct to the former colour set: white and black with more or less transparency will be used for all Xcerpt elements. Another distinction is done for textual Xcerpt keywords: they are written with italic font style.
3.1.1.3.1 Program
A Program consists of a finite set of rules (containing at least one rule). Because a program is meant to exist inside a development environment, programs do not introduce any visual representation. The rules (that are direct children of a program) are arranged as a list from top to bottom.
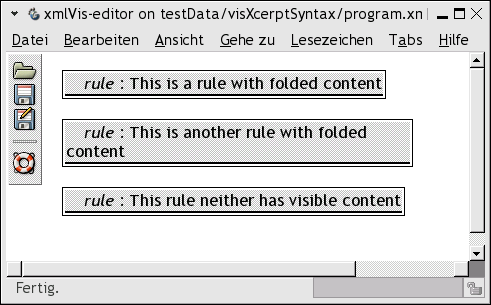
3.1.1.3.2 Rule
A rule is a container for construction and query patterns. The construction pattern can also be called head and the set of query patterns is also known as body. The semantics of rules is inspired by Prolog rules which in turn are Horn clauses with exactly one positive fact. The visual representation of rules is therefore also inspired by the traditional way of displaying horn clauses: head and body are arranged horizontally separated by an arrow pointing from the body to the head. The head is on the left, while the body is on the right. Because the semantic of the constructor is related to the content generated by the rule, the programmer may grasp with a quick glance at the left of the rule for what kind of content a rule is responsible.
Every rule is surrounded by a thin black border. At the top there is a title bar containing the keyword rule and an optional comment about the rule. Clicking the rule label folds the whole rule for information hiding purpose. A folded rule is represented by its title bar (still containing the rule keyword and the comment)
3.1.1.3.3 Head (Construction Pattern) and Body (Query Patterns)
The head like the program is not rendered in a special way, because it is determined by its position at the left of the rule arrow. The content of the head is displayed in the usual way inherited from the generic visualisation (which means that the content is arranged vertically)
The body is treated the same way as the head.
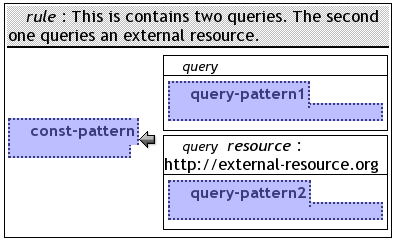
3.1.1.3.4 Query
Queries are the common members of a body. A query may have an optional resource on which it is applied. A query is displayed approximately the same way as a rule: a black bordered box with a title bar and the keyword query. The optional query resource takes the place of the comment in the title bar. Multiple queries are arranged vertically if they are and-connected and horizontally if they are or-connected. Because the semantics of multiple queries are a conjunction of them, it is considered to be unintuitive to hide some of them. Therefore they are not folded when their label is clicked.
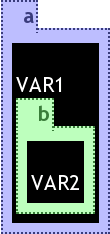
3.1.1.3.5 Variable
There are two different use cases for using variables in Xcerpt: variables placed somewhere inside a pattern and the so called as-construct, which restrict a variable to a sub-pattern. Variables are represented as black boxes with their name written in white at the top left corner inside its bounds. If the variable represents an as-construct, the restricting pattern is placed inside the variable's bounds. This may be confusing regarding the structure of the pattern: the aliased pattern is a direct child of the element containing the variable, and not a variable's child. To indicate this fact, a visXcerpt implementation may use a translucent black screening instead of a solid black colour for the variable background. This would indicate that the pattern inside the bounds of the variable has some relationship to its parent element -- the parent's colour is still surrounding the element. The translucent background is not implemented in the current prototype. Variables cannot be folded, because then empty variables and as-patterns would be indistinguishable. Variables partly implement the graph visualisation paradigm. If the mouse pointer is moved over a variable name, all occurences of this variable are hilighted.
3.1.1.3.6 All and Some
The Xcerpt All construct is only used in the head. It is represented by a black bordered box with a translucent screening background. The contained pattern is prefixed by the word ALL written in italic font, because it is an Xcerpt keyword. The SOME construct is currently not implemented. It can be used to take some results out of pattern matches. For this purpose a numeric value indicating how many elements are to be extracted from the set of matched elements is necessary. This number can be written between the pattern and the SOME- keyword (which is also in italic font). It is possible, that the number is styled like attribute values, to emphasize that it is an editable value.

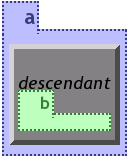
3.1.1.3.7 Descendant
The descendant construct is used to match content included as child at arbitrary depth from the descendant element's position. To depict this, a grey box with very strong bevel is used. A descendant need not be folded because the gain is marginal as it contains only a single element.
3.1.1.3.8 Regular expression
Regular expressions are labelled by the Keyword regexp. The regular expression itself is underlined with a dotted line. Regular expressions need not be folded because they tend to be one line long and only little would be gained. Regular expressions are only allowed in query patterns.

3.1.1.3.9 Logical connectives
The logical connectives AND, OR and NOT are displayed in different ways. Since NOT is currently not worked out in Xcerpt it will not be covered here, but it could be represented similarly to the all-construct.
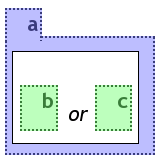
In accordance with various 2-dimensional logic notations, or is expressed through horizontal arrangement of its members while and connected elements are arranged vertically. This convention turned out to be the intuitive way for most people to the question how to associate vertical/horizontal arrangement to and and or in any abstract context.
Any number of elements can be or-connected. They are arranged horizontally in a white box separated by the or keyword.
Because queries in a rule are implicitly and-concatenated, not so much effort is done to visualise the and-construct. If used inside a query it may be indicated in a similar way as the or-construct -- by a white box .
3.1.1.3.10 User constraints
User constraints are work in progress in Xcerpt and not documented yet. A short explanatoion is given here.
User constraints can be compared to the condition boxes in QBE [zloof77query]. They provide data structure or schema independent constraints on variables. In Xcerpt, user constraints can be placed in the body. They may be children of and, or and query constructs. They are not part of the pattern structure they are located in. The position of user constraints according to the term structure is restricted by the occurrence of the variables they contain: variables used in user constraints may not violate range restriction (standardisation apart). It is likely that constraints are expressed as equations.
In visXcerpt, constraints are placed in so called condition boxes. A condition box currently does not use a special syntax: it is visualised as a generic XML element with name constraint in the Xcerpt namespace. Inside those constraints, no further visual constructs are introduced, except those defined. This means that the equations are written as in the textual representation, except e.g. document patterns or variable occurrences: these constructs are displayed as usual. This may lead to a kind of horizontally arranged list of visXcerpt constructs separated by keywords or symbols for user constraints. User constraints are neither implemented in Xcerpt, nor in visXcerpt.

3.1.2 Dynamic Aspects of visXcerpt
So far, only so called static aspects of visXcerpt have been proposed. At this stage, visXcerpt can be used as visualisation for Xcerpt programs. To be able to use visXcerpt for programming tasks without having to rely on textual Xcerpt, it is necessary to edit visXcerpt documents. For textual languages the editing process is clear, because the editing process for text is generalised -- any text document, no matter in which language (natural or programming) it is written, can be edited with the same text editor, e.g. Emacs, Word, Notepad or Vi. This section will first provide an overview about visXcerpt's editor model and then explain some facets in detail.
An visXcerpt editor should be aware of all the structures and components described in the former section. For textual editing, typing in new data (e.g. through use of a keyboard), cutting, copying, deleting and pasting are the most common editing primitives. These editing operations are bound to some kind of context locator -- usually a cursor or a selection. A cursor is usually located between two symbols and indicates the location where something may be edited or pasted. A selection is determined by two cursor positions: one position is obtained while the process of selecting starts, the other when it ends. The biggest difference between text (and other sequential information) and visXcerpt data is the explicit tree like structure of documents. Various (usually very short) sequences of elements are arranged in a hierarchy. Unfortunately the usual editor model with a cursor as separator, cut, copy and paste operation based on intervals is tailored for one dimensional data like text documents. Flattening the XML hierarchy by implying a document order would be necessary to apply the classic editor model to visXcerpt documents. As the solution is not intuitive, the concept of a cursor as separator is unsuited for visXcerpt. Instead, another approach is proposed to provide contexts for editing primitives: everything relevant for the editing process is supplied with a context menu containing the valid editing primitives for the context. Because actions are now bound to components rather than separators, it is likely that the editing primitives are different from those used for text editing. This difference is explained later.
Another condition for an editor model of visXcerpt is that one editing step should (as far as possible) lead from one valid visXcerpt program to another valid visXcerpt program. This way an explorative approach to the visXcerpt language for new users is encouraged -- "play around with the user interface, until what you see seems to represent what you have in mind". To accomplish this, the context menus should be dynamic, providing only state transitions that are not violating validity.
While restricting the editing process to transitions leading from valid states to new valid states is helpful for casual- and unexperienced users, experienced users may feel too restricted by this feature. These users may have concrete visXcerpt programs in mind and know efficient ways to assemble them based on snippets of older programs, leading to some invalid intermediate steps. A pragmatic answer to this problem is to provide an unrestricted version of editing contexts with the abilitiy to copy, paste and delete in all circumstances.
3.1.2.1 The visXcerpt Editor Model
As mentioned earlier, cutting, copying, pasting and deleting are the main editing primitives of visXcerpt. These actions are bound to contexts and contexts are bound to elements, CDATA sections or attributes. They are invokable through a context menu. These context menus can be seen as a static element, because every element has it's own context menu.
In order to paste without inconvenience, it is necessary to be able to paste into empty elements, at the beginning and at the end of a list of sibling nodes. This is accomplished through the special paste variants
- paste before:paste the buffer content before the context node below the same parent
- paste after:paste the buffer content after the context node below the same parent
- paste into (at beginning):insert the buffer content as first child into the context node
- paste into (at end):insert the buffer content as last child into the context node
Copying, cutting and deleting is applied to the context node (including its child nodes). Editing text like CDATA, attribute names/values is initiated by clicking them. Because clicking the element names leads to folding or unfolding them, editing the element name cannot be accomplished by clicking -- this feature is therefore located in the context menu.
An interesting aspect about editing is to support "learning by doing": the user is only supplied with editing operations which lead from one valid visXcerpt program to another valid visXcerpt program. One feature supporting this paradigm is to deactivate paste operations based on the paste buffer's content, if pasting would invalidate the selected context. Cutting and deleting is deactivated as well, if removing the context element invalidates the document. The current visXcerpt prototype does not support dynamic context menus. Integration of an XML type system comparable to DTD is necessary to check for validity of visXcerpt documents and therefore also for validity of editing operations.
While cut/copy and paste is convenient for modifying existing content, creation of new documents is not supported very well. For this purpose a template document is provided. It contains all visXcerpt elements and they can be copied from there and pasted into a new document if needed. Therefore the editor can be split into two frames, one with the new program to edit and one with the template document. The previously mentioned support of dynamic context menus for "learning by doing" may influence the design of template documents. If editing operations are restricted to non-invalidating operations, more element compositions should be provided as templates: a rule element for example must have a query and a head element to be valid.
3.2 Examples and Use Cases
So far Xcerpt's and visXcerpt's syntax have been presented. Since the semantics has not been introduced in detail, a comprehensive example section is provided to explain the usage of Xcerpt and visXcerpt through "learning by doing".
3.2.1 Simple visXcerpt Programs
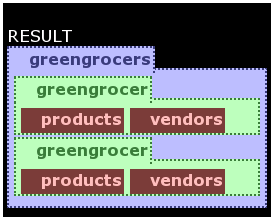
The programs in this section will present the elementary visXcerpt features in one rule. They rely on a simple document called the greengrocer database. It is kept short and easy to understand. The database is presented now using visXcerpt's generic element visualisation.

The visXcerpt term in figure ggdb represents the example database that the following examples will query. For layout purposes of print media, the visXcerpt pattern is split in three parts. It models a greengrocer database with the product inventory and the vendors providing the grocery. Every vendor has a name and a country attribute. Products are either vegetable or fruit and have a name and a vendor who delivered them. Furthermore they have a price that is either given in pieces or based on the weight.
3.2.1.1 Database Identity
For evaluation of the examples in the visXcerpt prototype a program and a goal (called query) are needed. In the following examples the goal is mostly irrelevant and will therefore always be the default goal -- an unconstrained variable called RESULT.
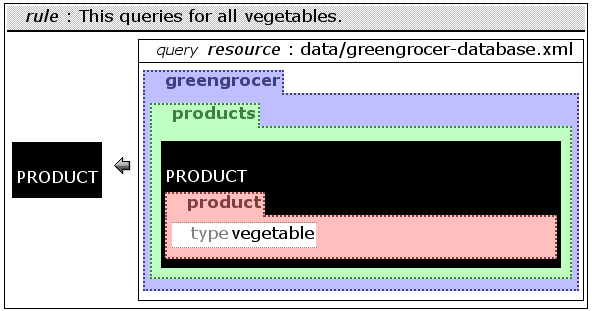
The program in figure ggid consists of only one rule. The rule has one query in the body that queries an external resource -- the greengrocer database. The query pattern consists of one unconstrained variable called ANYTHING. It thus matches the whole database. The rule's head and hence the construction pattern consists of the same variable. The result is therefore the database itself.

3.2.1.2 Querying for Parts of the Database
The following section will focus on query patterns. The result will always be bound to one variable. The head (or the construction pattern) will only consist of this variable. The result may consist of multiple elements and will therefore not always be well formed XML. In such a case the result consists of a disjunction of alternatives.
The overall structure of the program in figure ggallProducts is comparable to the former identity example. In contrast, the variable is now inside a pattern. Therefore only elements being inside a structure matching this pattern will be bound to the variable. All elements fulfilling the locational restriction are passed to the head and are therefore returned as result of the program.

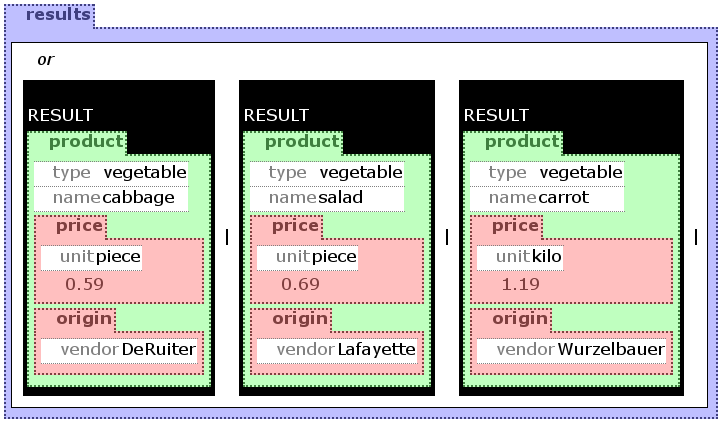
In the example on figure ggvegetables not all products will be returned. Instread, the result consists only of such products that are vegetables, i.e. have a "type"-attribute with the value "vegetable". In Xcerpt a variable is considered a "name" for a pattern and thus not part of the structure. Th visXcerpt on the other hand, the restricting pattern is placed inside the variable.
The descendant construct is a kind of wild-card
that matches any element in arbitrary depth. A
descendant construct has to contain exactly one
pattern. The corresponding pattern is then matched at any depth
below the descendant in the database. The example in
figure ggdesc behaves like the example in
figure ggvegetables and queries all
vegetables. It is somehow simpler, as the restricting pattern only
consists of the product-element. The variable containing
the product-element is surrounded by a
descendant construct. The root
greengrocer-element and the products-element can
be omitted.
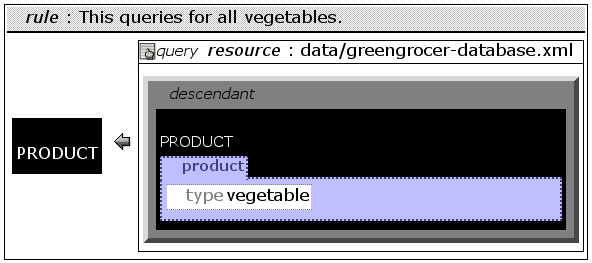
descendant construct. The query can be
compared to the former example. The pattern outside of the variable
can be obmitted because the occurence of product elements
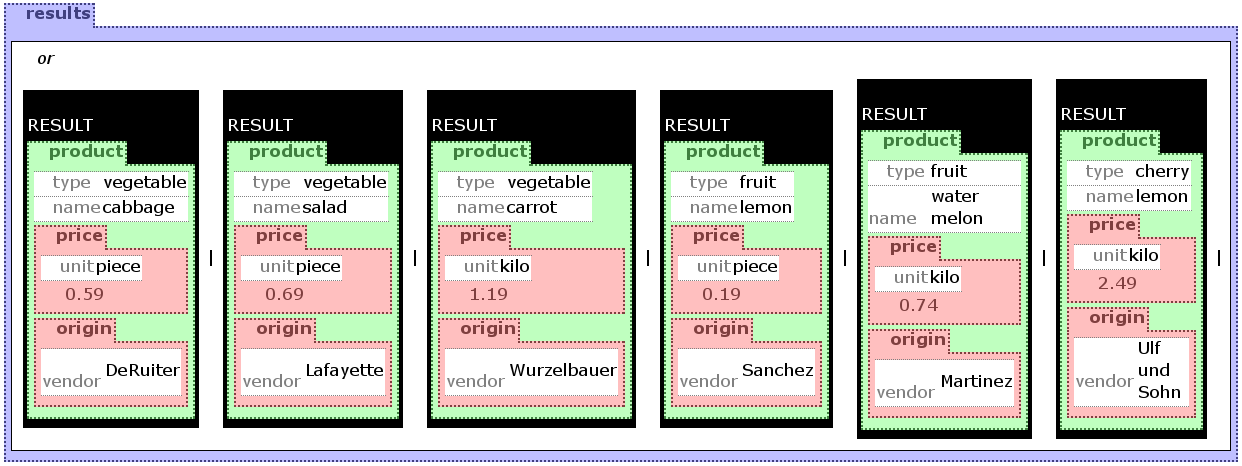
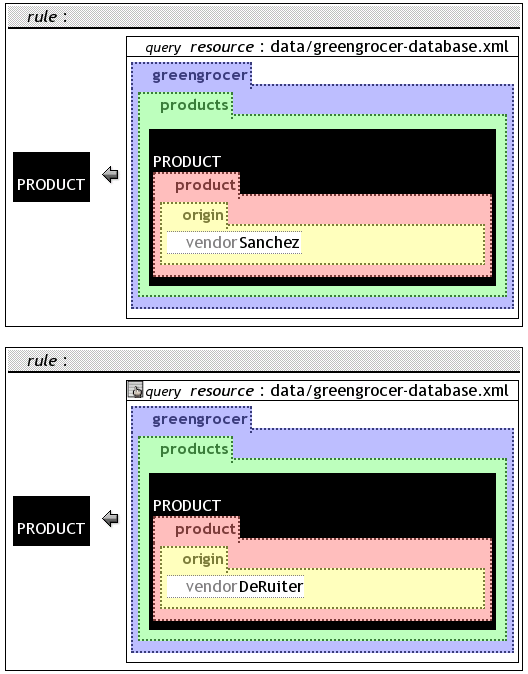
is clear in the context of the greengrocer database.On figure ggdisjunct the example uses a
disjunction with the OR construct to select all
products supplied by the vendors Sanchez and DeRuiter.
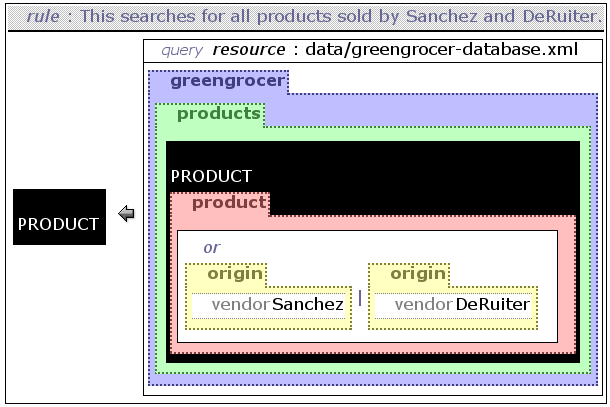
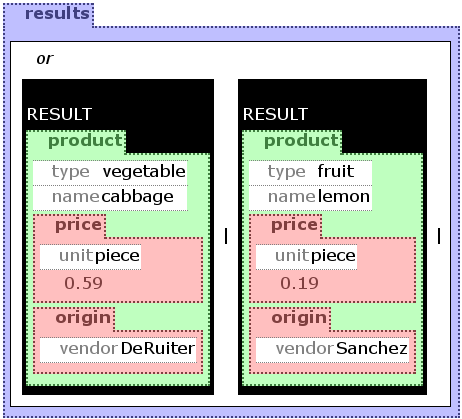
Although there exists an explicit AND construct in
Xcerpt, conjunctions are usually implicit. The conjunction is the
base for joins: variables shared between elements of a conjunction
are used to express the join. An example using a join over the
vendor attribute of product and the name
attribute of vendor to search for all products produced in
Spain is presented on figure ggconjunct.
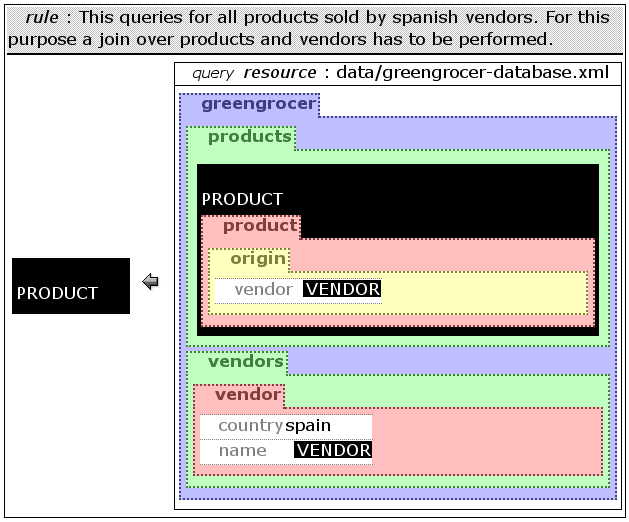
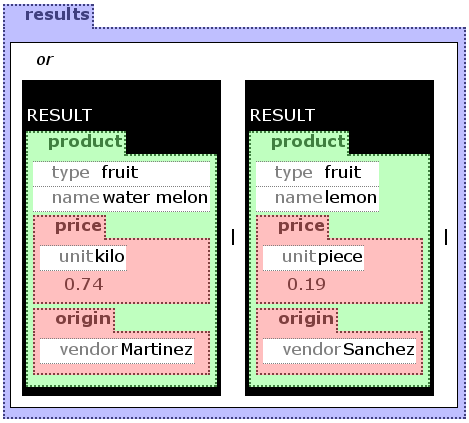
3.2.1.3 Using Multiple Queries in one Rule
To be able to query multiple resources at the same time, it is possible to put several queries in one rule body. Queries can be connected as disjunction or conjunction. If no conjunction is specified, a conjunction is built as the queries are arranged vertically. In a conjunction shared variables can be used to model joins.

3.2.1.4 Xcerpt Goals and the visXcerpt Query Frame
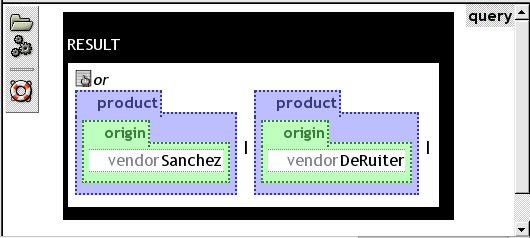
A goal is a query pattern that is applied to the whole program. So far, the goal was always assumed to be an unrestricted variable, therefore the result was only determined by the program. By using a goal, it is possible to refine the result of a program. A goal is similar to a query in the rule body and hence can be used to restrict the result. A program can then be compared to a library, with the goal as a selection of concrete functionality. The query of figure ggqueryGoal can be applied to the previously presented program that retrieved all product elements to restrict it to the output of the disjunction program.
3.2.1.5 The Rule's Head
While the focus so far was on the rule bodies the rule's head will be explained now. In former examples the head only consisted of a variable. To be able to use visXcerpt as transformation language, it is important to construct new content, but queries can only reproduce existing content of the queried resource. To produce new content, construction patterns are used. Construction patterns are located in the head of a rule.
The example of figure gg2DBs combines two resources into one document. It can be compared to the identity example. The difference is that the identity of two resources is associated to two variables that are used as child of the root of the result document.

The result document shown in figure gg2DBsRES is displayed using information hiding, because the content of the two greengrocer elements is similar to the greengrocer database presented earlier.
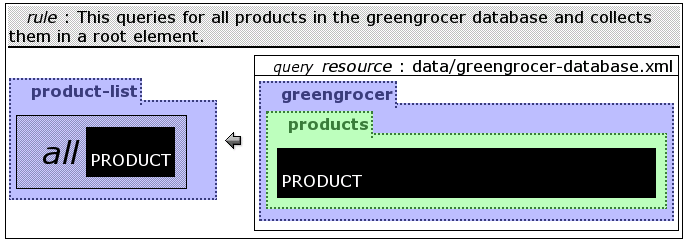
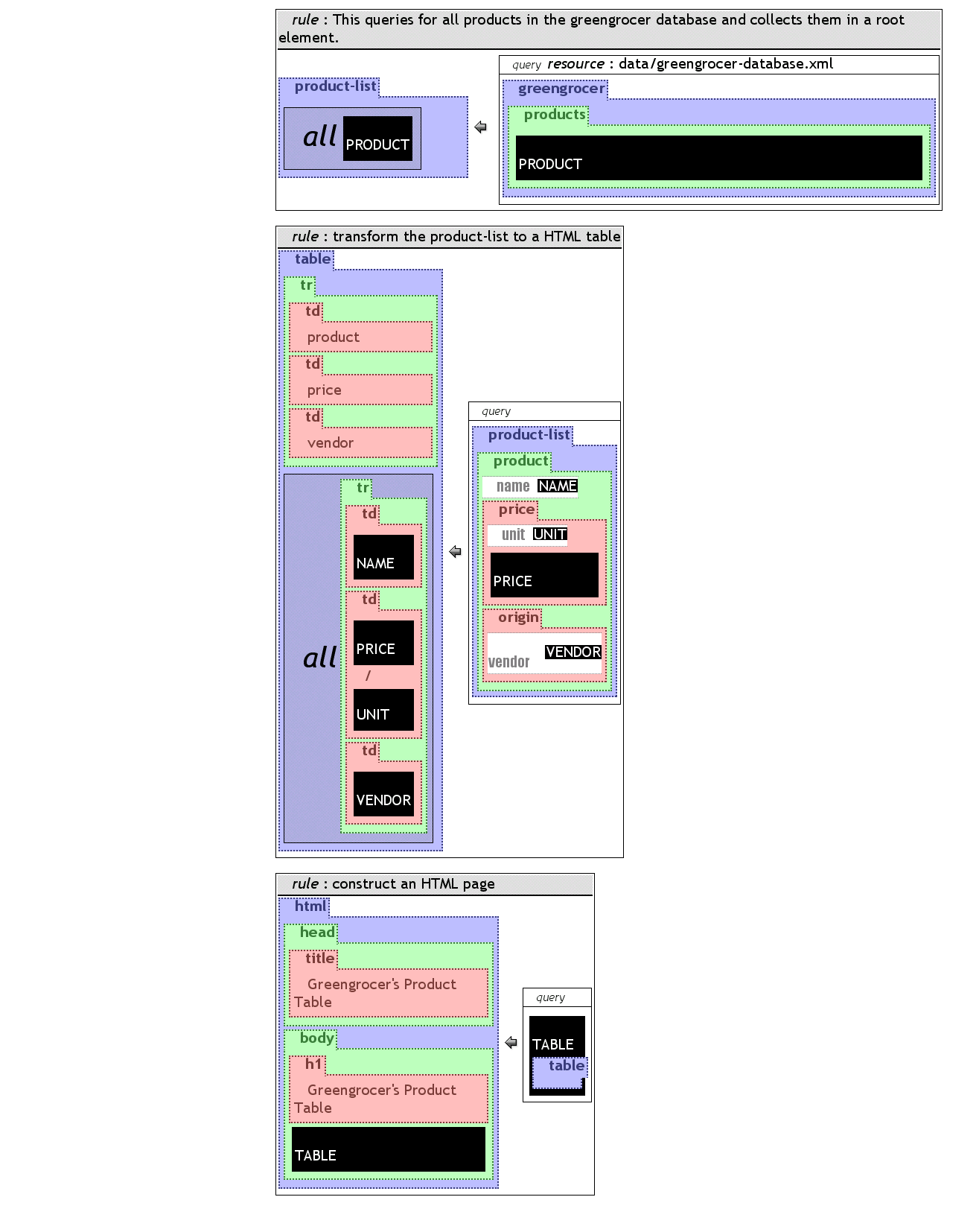
The example from figure ggprodList is a
modification of the product query from the previous section. All
products are collected in an element product-list. To be
able to collect all alternatives of the variable PRODUCT
into the product-list, the ALL-construct is
used. Without this, every product would have been packed into its
own product-list. This leads to a result consisting of
only one alternative, therefore the result is valid XML content.
The ALL-construct is only allowed in construction
patterns.

3.2.1.6 Programs with many Rules
In the general case, it will be desireable to write programs with more than one rule. As in logic programming rules are disjunctive. The variables are not shared among rules, the scope is local to the rules.
The example of figure gg2rules is comparable to the disjunction example presented earlier. The difference is, that it is implemented using two different rules.
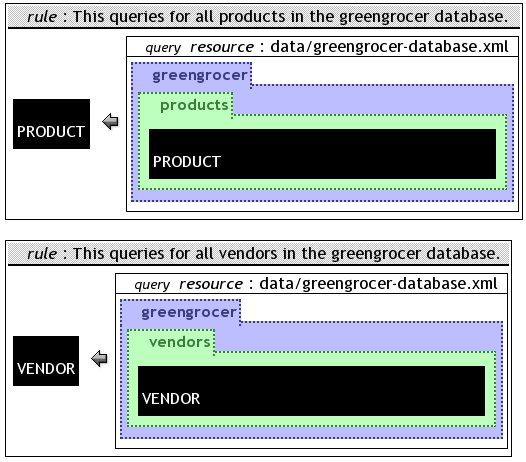
The example in figure gg2rules presented the disjunctive nature of many rules in a program, but this is not really useful compared to the shorter variant presented earlier (see figure ggdisjunct). Using multiple rules in a program is especially useful to build a library of rules. Concrete queries can then be expressed easily using the query goal. An example for this is the library presented in figure ggaccessLib. It can be used to query products or vendors, simply by using an appropriate query goal, like the one presented in figure ggqueryGoal.
3.2.1.7 Chaining Multiple Rules
A striking feature of visXcerpt is the so called chaining. Chaining is characterised by the process of using the result of a rule evaluation as input for further rule application. So far, rules had a resource associated as input. The query patterns operated on this input. If a query has no associated resource, chaining is applied. The program itself is used as input in this case. This leads to querying the output of all construction patterns in that program.
A simple example using the former product list is the following: an HTML product list is generated based on the product-list example. Because no module or include mechanism is defined so far in Xcerpt, the rule is added to the former example. One rule is used to build the HTML table by chaining it to the product-list and by transforming it. Another rule takes the table and embeds it in an HTML page. The only purpose of this rule is better readability in the sense of separation of concerns. To get the HTML representation, the query goal is restricted to the HTML representation by putting an html element into the unrestricted query goal variable. If the variable was not restricted in this way, three alternatives were produced by the program: the product-list, the table and the HTML page.
The use of chaining brings up the question about evaluation order: in which order are the chained rules evaluated? Two possible strategies are backward chaining and forward chaining. Both strategies are useful in certain contexts and there is continuing research about this subject. Both strategies are considered for Xcerpt.
Forward chaining is useful to pre-generate results. The operational semantics of forward chaining can roughly be explained as follows: every body/query that is productive, i.e. unifies a condition, is evaluated. A condition is either a resource specified in the query or the result of an evaluated rule. The queried conditions are consumed and the evaluated rule instantiates a new condition, based on its construction pattern. This process is iterated until a saturation is obtained, i.e. further rule evaluations are not possible. Multiple evaluation of the same rule is possible, if corresponding preconditions exist. Forward chaining is often used in deductive database systems. A practical use case for forward chaining in Xcerpt is to generate the web pages of a whole web site based on an Xcerpt program. All web pages are generated at once and can be submitted to a web server.
The operational semantic of backward chaining is the opposite of the operational semantic of forward chaining. The evaluation is driven by a goal. The goal induces only evaluation of rules with heads that can be unified by the goal. The queries of those rules operate the same way recursively. Backward chaining is useful to query large or infinite structures, because irrelevant rule evaluations are usually not instantiated.
Structural recursion is an interesting aspect that requires chaining. In structural recursion, expressions are usually stated on contexts and recursion is used to operate the same way on the child elements of the contexts. This is the common behaviour of XSLT. It should be noted that the current Xcerpt prototype fails or does not terminate on the programs presented in the following. However, the necessary modifications are currently being investigated. This concerns all programs where information is passed to a variable in the head with the intention to be matched in the body. The recursions are now explained from the point of view of backward chaining.
To express structural recursion in logic programming, it is necessary to operate on a context. Because rules are chosen based on the unification with a query pattern, the context needs to be known in the query pattern. To evaluate a rule that is meant to operate on that context, the rule's head needs to provide a subpattern that can be unified with the context. This sub-pattern can be seen as input parameter. The result of the application needs to be transferred to the initiating query pattern. Thus the query pattern has a variable that matches a part of the head of the rule that evaluated the context. This part will be called output parameter.
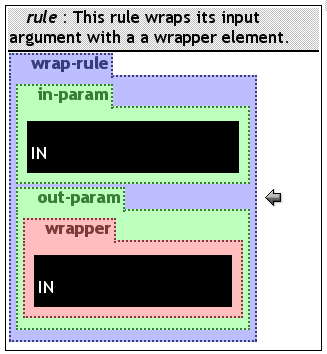
In figure wrapFun a simple wrapper-rule is presented, which wraps its input parameter into a wrapper element. It is apparent that this rule has no query body. In Prolog these rules are called facts. The empty body has to be interpreted as true because it can be seen as an empty conjunction. The arrow may be replaced by another symbol for rules without body (maybe a dot). The current prototype does not support facts.
The use of in and out parameters, as mentioned above, can be compared to a function evaluation. An interesting aspect is that the reversal of a function application can be done with the same rule by exchanging the role of input and output parameters.
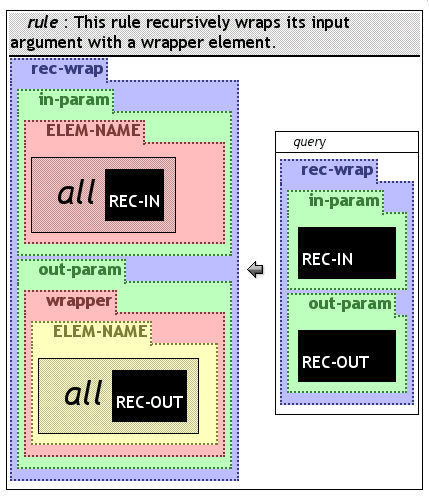
The mechanism of parameter transfer between rules is now used to build the structural recursive transformation in figure wrapFunRecursive.
The rec-wrap-rule is capable of wrapping elements and all its child elements recursively. For this purpose a further extension is necessary to the Xcerpt prototype: element names have to be capable of holding variables. This extension has already been investigated, but has not yet been implemented; however it is not likely to pose any problems.
The program in figure wrapFunRecursive consists of one rule. It is similar to the former wrap-rule program. The element name ELEM-NAME has to be interpreted as variable in this example. The input inside in-param is decomposed into the top level element and the child elements bound to the REC-IN variable. While the decomposed element name is used to construct the wrapped element inside the out-param element, the REC-IN variable is used in a recursive query of the same rule. The output of the recursive query is used to complete the out-param section of the construction pattern.
3.2.1.8 Practical Example - a core crawler for the web
This section will present a little library useful for construction of web crawlers. For this purpose variable resources are used. Since the current visXcerpt prototype does not support variable resources, the Xcerpt notation is used for this purpose -- a dollar-sign is used as prefix for the variable name. [FOOTNOTE] : Prefixing a dollar-variable also works for attribute values or CDATA, because the transformed document is valid Xcerpt. Because currently variables in attribute values are broken, this feature is not disabled. Obviously, the recursion through the link structure of the WWW will not terminate in most cases, as the WWW contains circular link structures. Nevertheless the core of this web crawler is a simple recursion through the WWW. The recursive core transforms the WWW into an infinite document. This XML representation is not intended to be materialised, but should be chained to user supplied visXcerpt queries. Apparently, this infinite recursion assumes the Xcerpt processor to defer the construction and hence also the resource loading until it is relevant for a concrete query.
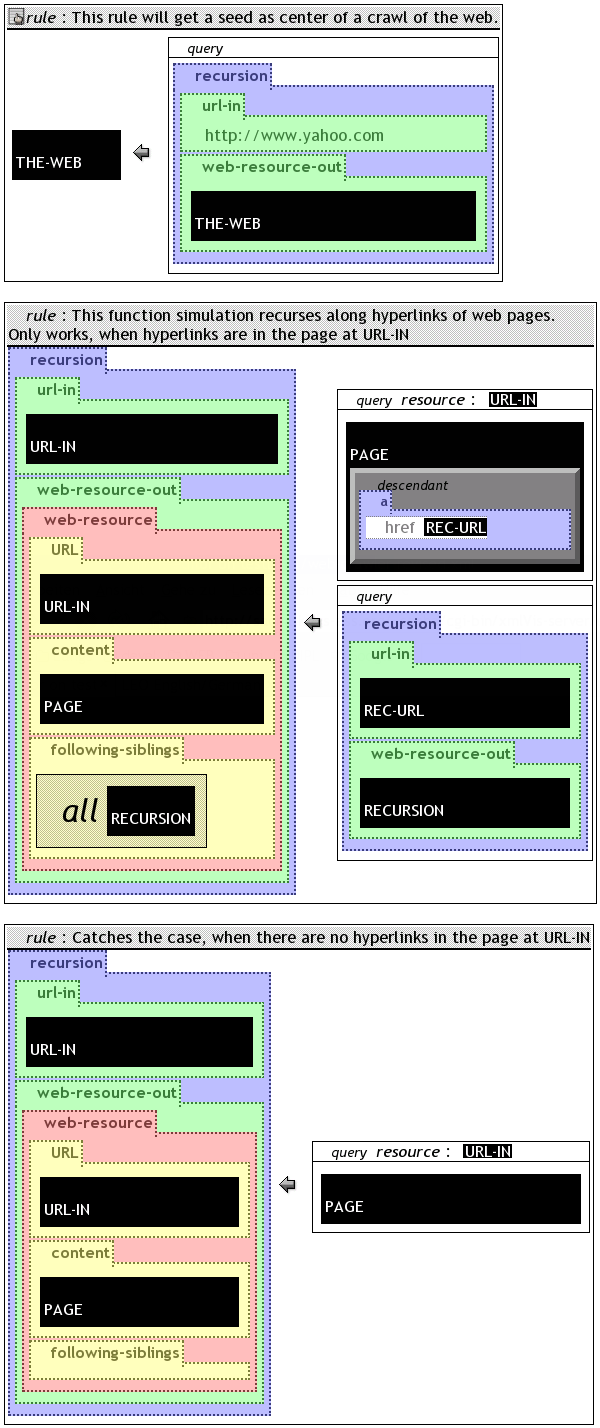
The naive crawler example in figure naiveWebCrawler explains how a recursion over the WWW structure can be expressed. To access most of the web it is sufficient to access a page of the so called web core. The web core consists of all pages that are accessible through at least one path of arbitrary length from another page of the web core, while having a path to all other pages of the web core. Those paths are established through hyperlinks. Yahoo! is a popular member of the web core with a very high "out degree" [FOOTNOTE] : The out degree corresponds to number of hyperlinks of a web site to other pages. For this purpose the first rule initiates the recursion with the Yahoo! home page and wraps it in an elementweb-resource [FOOTNOTE] : The wrapping is used to have an uniform access point to all web pages, because the HTML-Root element may be spelled differently or may even be omitted. element. The second rule does the same, except that the resource is variable. A second query in the body matches any web-resource element the program constructed (or will construct) and retrieves URLs in hyperlinks. Through a join, the URL is tied to the resource querying the page.

A problem with this approach is, that a querying and restricting rule can not make any assumption on the progress, e.g. the depth of the search or if the URL has already been visited. For this purpose, the web-resource element would need further extensions, like the URL it originates from, and information about its environment in the WWW topology. The extended crawler constructs the infinite document mentioned earlier as spanning tree of the WWW. Circular structures are not cropped, because an application may rely on them. Hence the result document may have infinite depth. A web-resource element is now extended by an URL element, a content element containing the concrete page and a following-siblings element with all web-resources accessible from this page through a hyperlink. Not covered is the aspect of differentiating between relative and absolute URLs. To implement this feature the regular expression construct is useful.
The example in figure revisedWebCrawler is proposed to overcome the shortcomings of the former example. The program consists of three rules. The first one is used to strip the function emulation pattern off the desired web-resource document. The second and third rules are used to recurse through the WWW's link spanned graph structure. The third rule is used to handle pages without hyperlinks. The second rule cannot handle them, because no bounds can be found for the variable REC-URL, therefore the rule fails. The second query of the first rule is used to recursively call the recursion function. Still unhandled by this example are relative URLs.
3.3 A Prototype for visXcerpt
A main task of this thesis was the implementation of a prototype for visXcerpt. This prototype has been used to evaluate and refine the concepts of visXcerpt as presented earlier. Among the most important evaluated features are:
- readability of the visualisation: The inspiration for the use of colours came after a monochrome visualisation turned out to look too cluttered
- usefulness of information hiding: while visualising large documents, it turned out to be useful to include information hiding. For the visualisation of databases it is more comfortable to start with a fully folded view, while this is unpleasant for visualising Xcerpt programs.
- editing concepts: The paste operation of the editor model was
refined to contain the
paste into at beginningpaste into at endpaste beforepaste after
operation to fulfil all editing tasks comfortably. However, the editing process is still slightly clumsy and various high level or macro operations have to be investigated.
Last but not least the prototype was important for the authoring of visXcerpt examples in this thesis. Because of time and capacity restriction and because not all features are relevant for the proof of concept, not everything proposed in the former section about the aspects of Xcerpt have been implemented. The implemented parts are:
- the generic XML visualisation restricted to trees
- most static aspects of visXcerpt
- the untyped (non-validating) editing aspects
- persistence (the ability to open and save documents)
- presenting the result of visXcerpt program evaluation
The aspects that have not been implemented are:
- schema support and type checking of editing operations : This feature is not relevant for the evaluation of visualisation and editing aspects. The application design is separated in a server and a web browser application. This feature would require a lot of information flow from the client to the server for all editing operations modifying the document. To have pleasant user interface responsiveness some optimisation would be necessary.
- context sensitive editing : The restriction of editing operations to transitions that result in valid documents, and furthermore support for context sensitive creation of valid elements would be required. For this feature the former mentioned schema support is an important precondition.
- general graph operations : Due to lack of time they have not been implemented yet. Some parts of the graph support can be found in the behaviour of variables.
3.3.1 Target Platform
For the purpose of "separation of concern" a major implication was to use the Xcerpt prototype for program evaluation. This way the prototype is only focused towards translation of visXcerpt programs into Xcerpt programs. Another important feature was the abstraction away from layout aspects: visXcerpt programs do not contain layout and positioning information as many other visual programming languages do. A visXcerpt program can be translated into an Xcerpt program and vice versa. This enables an unambiguous translation from Xcerpt to visXcerpt. Hence Xcerpt can be used as intermediate format for persistence and transfer of visXcerpt programs. VisXcerpt is a pure in-memory representation of Xcerpt.
The abstraction away from layout and positioning information reveals the need for an automatic layout based on structural information. For this purpose a standard web browser can be used. HTML is the structured information that is rendered by the web browser. Using web standards for client user interfaces brings a high degree of system independence and benefits of highly optimised rendering engines. Forward compatibility with upcoming web browsers is very likely.
As some features are not available in web browsers, a web server based service is necessary. Persistence of visXcerpt programs is one of the reasons for this web server based service: some mechanism for loading and saving programs is necessary. Furthermore, standard web browsers do not integrate the Xcerpt prototype. The use of a Java applet is inappropriate, because various Xcerpt prototypes exist in different implementation languages other than Java. Furthermore, the persistence problem can not be solved easily in Java, due to file access restrictions.
Todays web browsers incorporate various web standards that can be used to implement web application client views. The following were used to implement the client side view of visXcerpt:
-
HTML : This is the core of most modern web
browsers. HTML incorporates properties of specific-, generalised-
and generic- markup languages. It is therefore possible to specify
the style and the structure of documents. There is actually a
tendency to deprecate the specific aspects -- and therefore the
elements responsible for document style. The styling aspects are
actually shifting towards CSS.
The generic aspects of HTML are realized through the use of so called
class-attributes.class-attributes can be used together with most HTML elements, but the suggested semantics will always be a combination of the user supplied class-semantics and the elements core semantics. AH1-Element (a major heading) with a class attribute value X is likely to be interpreted at the same time as heading and as an X object. To prevent this semantic overloading, there exists the semantically almost untainted elementsdivandspan. The only interpretation ofspanis that it is an inline element of the surrounding text. It will therefore be part of the text flow.divis interpreted as some kind of section and will therefore start a new block of text. - CSS : CSS is used to specify the style of HTML markup. The capabilities range from text- and background- colour, font -style, -size and -family to arrangement, indenting, automatic text creation, list numbering style and simple interactive features like link action style. CSS is the first choice to make classes of elements visually distinguishable. Nested structures can easily be made apparent with CSS through the use of borders and colours. A static core mechanism for information hiding is available through various element visibility properties.
- ECMA-script : Based on Netscapes scripting language Java-Script [FOOTNOTE] : Java-Script is not the same as Java. The name has been chosen for marketing reasons, to benefit from the popularity of Java in Java-Script's early days. It was initially intended to be called Live-Script. the ECMA standardisation organisation established ECMA-script. It is a subset of Java-Script implemented by all modern web browsers. It lacks Netscape's and Internet Explorer's specific features. ECMA-script is an imperative, dynamically typed and object oriented interpreted programming language. ECMA-script's object orientation is not based on class inheritance as used by most object oriented programming languages today, but on prototype delegation. Nevertheless, class inheritance can be simulated using prototype delegation if desired. ECMA-script is used to include calculated content into HTML pages, to accomplish various HTTP based network communication with a web server and to dynamically react on user interaction.
- DOM : to be able to alter the structure of an HTML document dynamically through ECMA-Script, various incompatible solutions were developed by competing browser developers. An effort called DHTML was launched to unify the way how content could be altered dynamically. The base for this is an application programming interface (aka. API) to access and modify the document. This application is called document object model, in short DOM. DOM provides a tree interpretation of the document where elements are nodes with lists of children and a parent node. The API is an official W3C recommendation. The standard contains the API as interface specification for Java, ECMA-script and for CORBA. It has now been adopted by most modern programming languages as a API to process HTML and XML content. The DOM API is implemented in most modern web browsers and provides access to the loaded document.
As mentioned earlier, visXcerpt is related to Xcerpt through a reversible transformation. Xcerpt itself provides an XML notation besides the more compact term notation introduced earler. To get a visXcerpt instantiation of an Xcerpt document, a transformation from an XML notation to something using the former web standards is necessary. Because there exists an XML dialect of HTML [FOOTNOTE] : The XML dialect of HTML is called XHTML and is a W3C recommendation, an XML transformation language should be suitable for this task. Xcerpt (and hence visXcerpt) is suitable for this purpose, but some technical inconveniences with the prototype at the time of writing this diploma thesis discouraged the use of Xcerpt for a runnable prototype. The reasons was mentioned in the examples section earlier and is related to recursive function emulation. XSLT was used for the prototypic implementation of the Xcerpt-to-visXcerpt transformation.
3.3.2 Modelling the Prototype
This section will explain how far CSS is usable for the prototype implementation, why the XML notation of Xcerpt cannot be directly styled with CSS and what kind of HTML structures are necessary to represent Xcerpt. The need of a reversible transformation will be motivated and a generic mechanism for reversible transformations will be presented.
3.3.2.1 A Motivating Example
This section will roughly explain how a pattern element (called generic element) is translated into its visual counterpart. The real translation is slightly more complicated, because it contains further elements like buttons with event handlers and layout elements.
A first idea for the prototype was to use CSS on XML to specify a visual rendering for Xcerpt documents. For this purpose an XML aware browser could have been used. It turned out to be impossible, because default XML browsers cannot display an XML element name. The element name is a major information in visXcerpt terms that cannot be visually omitted. Therefore a transformation is necessary, to extract information like element names and attribute names. The target language chosen to reflect the Xcerpt documents is HTML.
Spoken in abstract terms, the main concept of visXcerpt is to
use nested objects to represent structure. The nested structure can
easily be mapped to nested HTML div-elements with a
class attribute, while the visual representation is controlled
through the use of CSS. Borders around each element and background
colouring can easily be made with CSS. With CSS margins and
paddings of the div-elements a pleasant feeling of
nesting and indenting is given.
While the nested structure is easy to represent, the fact that
the label is outside of the nesting is problematic: For the element
name, a span-element can be used. It can be placed
along with other span-elements, because it is not
interpreted as a text block. This feature is needed for the
information hiding aspect. Unfortunately the span
cannot be placed inside the div, because it would not
be located outside, as specified. For this reason a generic
visXcerpt element needs to be translated in two elements, one for
the label and another one for the content.
By now it has been explained, why CSS and Xcerpt are not enough to implement the proposed visXcerpt language and a rough sketch about how a generic translation of pattern elements may take place have been given. If a translation for Xcerpt is necessary, a translation back from visXcerpt to Xcerpt will be necessary, at least to be able to delegate program evaluation to an existing Xcerpt implementation. A straightforward solution would be to write two translations. This approach has a major drawback: functional dependency of both transformations is very high and therefore modification on one side leads to inconsistency on the other side. The solution presented now, prevents this dependency of transformation and backward transformation through introduction of a meta-model and a generic backward transformation process.
3.3.2.2 The lXr XML meta-model
The lXr XML meta-model is an annotation mechanism for XML documents. It is used to embed information into a host document about how to generate a structurally similar, but simpler document based on the content of the host document. The lXr XML meta-model is explained independently from the visXcerpt language. It is also independent of HTML. An lXr processor is able to transform the host document without any further program or document needed to specify the transformation. In this way, the lXr transformation process differs from Xcerpt, XSLT and other transformation languages that usually involve two documents in the transformation process: one as data source, the other one as transformation program. Nevertheless, the processor can easily be written as Xcerpt or XSLT transformation program. The lXr annotations are specified using XML attributes, optionally in a separate namespace. This way lXr annotations usually do not disturb the application structure of the host document, it should be usable for most common XML based applications. This was an important property while developing the visXcerpt prototype, because it was not clear if the intended features could be modeled in HTML. In case of HTML related problems, SVG [FOOTNOTE] : SVG is a markup language used for specification of vector graphics. It also contains grouping constructs usable to model nested structures. It is a W3C recommendation. would have been used. The lXr meta-model is also applicable to SVG.
3.3.2.2.1 Properties of host Documents
The lXr XML meta-model makes some assumptions about the host document:
- Every node of the derivable document is represented by one or many sibling nodes in the host document. If many host nodes represent a derivable node, the host nodes are in a sequence not interrupted by host nodes of other derivable nodes.
- If derivable nodes are siblings (or attributes are from the same element), their supporting host lists are also siblings
- CDATA, element and attribute names, attribute values and namespaces of the derivable documents are always CDATA nodes of the host documents. They are isolated CDATA nodes without further irrelevant CDATA.
- The host nodes of a child node of a derivable node are descendants of one of the host nodes representing the derivable parent node.
The properties of the host document make clear that the host document always has more nodes, than the derivable document. The lXr annotation is done with the three attribute classes described now.
3.3.2.2.2 lXr Annotation Attributes
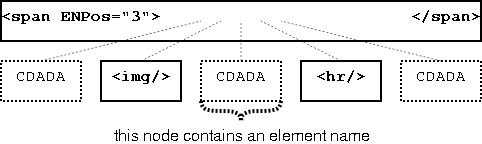
The first attribute class indicates the location of CDATA that represents textual information of the derivable document. They have a numerical value that indicate the position of an element containing the CDATA as sole child node. They indicate the position in the list of child nodes of the element containing the annotation. The concrete attribute names are:
-
ANPos: Indicates an element containing an attribute name. -
AVPos: Indicates an element containing an attribute value. -
ENPos: Indicates an element containing an element name. -
CDPos: Indicates an element containing CDATA. -
NSPos: Indicates an element containing a namespace URI.
The host document structure allows a list of siblings to represent one derivable node. For this purpose, an annotation attribute to determine the list is necessary. Because two host element lists are always disjunct, an indicator for the bounds of the lists is used. Because it is possible that a list contains, starts or ends with some CDATA that cannot be annotated with attributes, the bounds are indicated at a suitable node in the list. The meta-model is named after those bounding indication attributes -- the lXr attributes. The l stands for the length of the list on the left side of the element containing the lXr attribute, the r for the length on the the right hand side. There exist three different lXr attributes and the X is a place holder for three different characters:
-
lEr: Indicates a list of nodes hosting an element. -
lAr: Indicates a list of nodes hosting an attribute. -
lCr: Indicates a list of nodes hosting some CDATA.
For example an attribute lEr="3,5" indicates that
the host node list consists of 9 nodes: the actual one containing
the lEr attribute, the three previous sibling nodes and five
following siblings. This way it is easy to implement the previously
described generic visXcerpt element consisting of one
div-element and one span-element and
optionally up to three CDATA sections of whitespace for HTML source
code indenting.

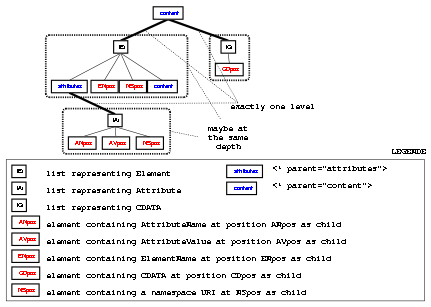
With the lXr attributes and the textual positioning mechanism it is still possible to specify host documents where "digging past" the direct child nodes is possible. The second condition on host documents prevents this: if all sibling nodes are hosted by sibling lists, there exists a common parent of those nodes. Therefore there is exactly one descendant below an element-host-node-set that is the parent of the children's host lists and one descendant indicating attributes as child nodes. In the context on an host node document fragment, the path down to an element marked as parent must not contain any other parent marked node.
-
parent="attributes": This marks an element that is the parent of node lists hosting attributes. -
parent="content": This marks an element that is the parent of node lists hosting elements and CDATA.
With those ten attribute types, it is possible to embed information about a derivable XML document into a host document. It is possible to model elements, CDATA, attributes and namespaces for elements and attributes. XML comments, processing instructions and entities are not expressible using the lXr meta-model. The following section will describe the role of the lXr meta-model for the visXcerpt prototype, which reaches beyond reverse transformation and is of major relevance for the dynamic aspects.
3.3.2.2.3 lXr and the visXcerpt prototype
One advantage of the lXr meta-model for the visXcerpt prototype is the generic reverse transformation. If Xcerpt programs are translated into visXcerpt programs that are enriched with lXr annotations, modifications of the transformation program are independent of the backward transformation. The consequence is, that the transformation step needs to be enriched with lXr attributes. There would be no advantage beyond functional dependent transformation and reverse transformation, if the lXr annotation would have to be manually supported. It turned out, that transformation programs that fulfill certain properties can be automatically enriched with lXr annotations. For this a transformation program has been written, enriching the construction patterns of a transformation program with lXr annotation attributes. A non-enriched transformation is called a theme. The term "theme" is widely used in desktop environments and graphical applications for a package or file that controls the overall look-and-feel of the applications.
As mentioned, a visXcerpt theme is a transformation program that is transformed into another transformation program with lXr annotated construction patterns. This lXr enrichment program is independent of the theme that has to be translated, it only depends on the transformation language the theme is based on. The transformation language chosen for theme authoring was a slightly modified and reduced subset of XSLT. The theme specification language has not been formally specified, because this is out of the focus of this thesis. It is implicitly specified through the themes and the transformation program used to enrich the themes with lXr annotations. Xcerpt and visXcerpt would have been the first choice solution as theme specification language, especially as an educative example for boot strapping of visXcerpt, but unfortunately, the current Xcerpt prototype lacks some features needed for transformations based on structural recursion. The features are actually being developed. In the chapter about examples, there is an example describing the use of structural recursion in Xcerpt. An Xcerpt based theme would use similar rules.
Another striking feature of the lXr meta-model is the usefulness
for the editing process of visXcerpt. Because the whole information
about the Xcerpt document is inherent in the visXcerpt document,
which itself is an HTML document, modification of the HTML document
is reflected in the Xcerpt document. It is in fact possible to edit
a visXcerpt document using an HTML editor, if new components are
generated by copying, pasting and modifying existing components. By
copying and pasting the lXr annotations are preserved and the
modifications are delegated to the hosted Xcerpt document. A modern
web browser provides the ability to modify a document in memory
using ECMA-script and the DOM API. HTML documents using ECMA-script
to modify themselves through the DOM are known as DHTML (short for
dynamic HTML) documents. visXcerpt documents are DHTML documents.
The HTML onClick, onMouseOver and
onMouseOut event-handlers are used to invoke
ECMA-script functions modifying the visXcerpt document. The
ECMA-script functions needs lXr annotation awareness. If e.g. an
element is to be copied, the responsible function needs to find out
which DOM nodes are concerned. For this purpose an ECMA-script
library has been written, providing lXr meta-model navigation,
selection and query functions. Its functionality is similar to the
DOM API's functionality, but additional awareness about hosting and
hosted elements is supplied.

3.3.2.3 Assembling visXcerpt's Client Components
The most important components of a visXcerpt document are summarised as follows:
- The lXr annotated transformation of the Xcerpt documents are enriched by event handlers that are mostly based on
- the generic lXr annotation aware ECMA-script library. The library performs editing operations, reverse transformation and information hiding operations. The concrete look-and-feel of the visXcerpt document is controlled by
- various CSS documents. These style sheets control the fonts, the colours, the margins, paddings and indenting and the borders of the boxes representing elements.
Furthermore some objects relative to the whole visXcerpt document are necessary:
- menus for editing operations. They are displayed when an editing operation icon on an element is clicked. The context for the operations of the menu is the element whose icon was clicked. The visual location of the menu is near the editing operation icon (based on the screen location of the mouse event).
- icons assembled in a tool bar for loading, saving and helping.They are relative to the visual presentation context of the visXcerpt document (e.g. a frame or a window), therefore they are always visible in a tool bar and do not require the context menu.
All those components are assembled in a DHTML document. It was decided to keep the ECMA-script functions and the CSS expressions as external documents, because they are not in XML syntax and because they are immutable.
The current visXcerpt prototype provides a framework of useful
client configurations, an Xcerpt result presentation and a minimal
file selection document for the server-side stored repository of
Xcerpt (or XML) documents. The Xcerpt result configuration is again
strongly based on the pattern presentation of visXcerpt. A result
consists of variable constraints. There may be an arbitrary amount
of results for each variable. They are interpreted as disjunction.
For this, a variable has an or-ed set of variable free
patterns as result. visXcerpt's OR construct is used
for the disjunction, each variable is represented by an element
called result with an attribute called variable-name.
The content is a disjunction or optionally directly a result, if
only one result occurs.
A client configuration is a frame set of visXcerpt documents. Copy-and-paste operations can be performed between the documents of such a frame set. Currently three configurations exist:
- Plain editor : This configuration consists of only one visXcerpt document. It is not possible to use copy buffers from other documents. The plain editor is mainly used for screen shots, because it is easy to bookmark [FOOTNOTE] : Most web browsers behave strange while using bookmarks of frame sets., resize and because it has the least screen usage overhead.
- Two vertical frames : This turned out to be the best compromise between screen size usage and flexibility. Two visXcerpt documents can be edited simultaneously, they share the same copy-and-paste buffer.
- Interactive Xcerpt query frames : Three frames are available. One on the left is used for editing a visXcerpt program, two are stacked on the right side, and the bigger one contains a visXcerpt template document. It is configured to be non-editable (only the copy operation is active). This frame contains all visXcerpt components. It is intended to be used for copying new instances of visXcerpt components. Pasted into the editor frame on the left, they are editable again and can be specialised for the users query. Below is a smaller frame that is intended to contain a query. The tool bar provides a special icon for query execution. If clicked, the query is applied to the editor frame on the left. The result is presented in a new window with a plain editor configuration, thus it can be edited or saved easily.
Loading, saving, query execution and assembling of visXcerpt documents can not be performed by the web browser. Those operations are handled by the visXcerpt server explained in the next section.
3.3.3 The visXcerpt Server
The visXcerpt server is implemented using the common gateway interface (aka. CGI). CGI is a communication standard between web servers and server applications. Based on a given query, the applications are intended to produce result documents returned by the web server. The CGI uses environment variables and standard input to inform the application about the request, the standard output of the application returns the result document (including parts of the HTTP header, like the content type). The CGI is implemented on almost all common web servers.
Any Xcerpt program can be transformed to a visXcerpt program and vice versa without information loss. For this reason the shorter Xcerpt notation has been chosen for persistence. e.g. file storage. The first task of the visXcerpt server is to transform a request for an Xcerpt document into a visXcerpt document and to send it to a web client. Furthermore the server dispatches according to the users preferences the right visXcerpt transformation theme and the appropriate CSS document.
Two special requests to the visXcerpt server are
- saving documents : using a HTTP post request, the web browser sends the Xcerpt document and the intended filename to the server. The transformation from visXcerpt to Xcerpt is fulfilled by the web browser using the ECMA-script lXr library. The advantage of client side transformation is reduced data transfer -- Xcerpt documents are about 8 to 10 times smaller than visXcerpt documents. [FOOTNOTE] : It is useful to reduce the data the client has to send to the server. Actual network technologies indicate a drift towards asymmetric network bandwidth, where providers have large down streams to their customers, while customers have small up streams back to their provider. Reducing the data to transfer through the upstream is therefore important. The server stores the document and returns notification about the success of storing the document. The notification is displayed in a small window opened by the web client. For security reasons, the document loading and storing is restricted to a special folder on the servers file system.
- evaluating a query on a program : using the HTTP post request, the web browser sends the Xcerpt program and an Xcerpt pattern used as query for the program. The visXcerpt server dispatches the program and the query to an integrated Xcerpt prototype. The result of the Xcerpt prototype is transformed using the user's preferred visXcerpt theme and is returned to the client. The client displays the result in a new window.
For the server side XSLT transformations (used for lXr annotation of the themes and for theme application) xsltproc, a libXSLT based XSLT processor has been used. To glue all components (XSLT processor, Xcerpt prototype, user preferences handling and file storage) together, the scripting language Python has been used. Beside the author's personal preference for using python, the availability of a python library wrapping the Xcerpt prototype with a comfortable API was a reason for choosing python as implementation language. The visXcerpt server consists of less than 500 lines of python code in 13 modules.