











© 2006 Tim Furche, Benedikt Linse, François Bry, Dimitris Plexousakis, and Georg Gottlob
:= research & development
endeavor aiming at "hidden" Web problem
“The Semantic Web will bring structure to the meaningful content of Web pages, creating an environment where software agents roaming from page to page can readily carry out sophisticated tasks for users.”
Tim Berners-Lee, Jim Hendler, and Ora Lassila: The Semantic Web, Scientific American, May 2001.
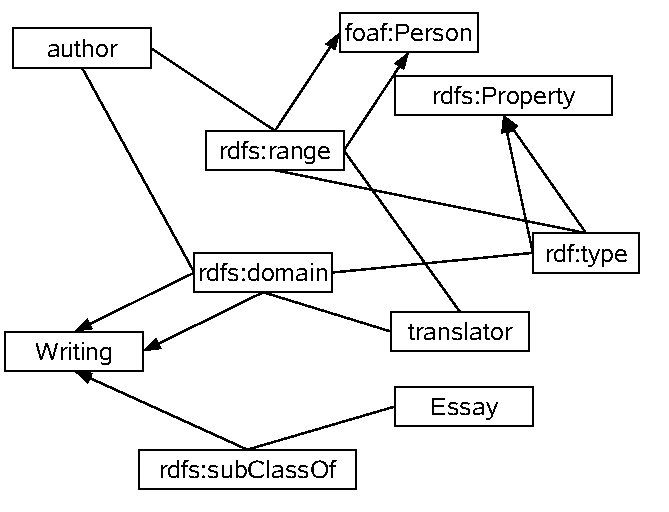
rdf:type type of resources)rdfs:subClassOf (class-subclass relationships
between subjects/objects)rdfs:subPropertyOf (property-subproperty
relationships between properties)rdfs:Class (the class of all classes)rdf:Property (the class of all properties)
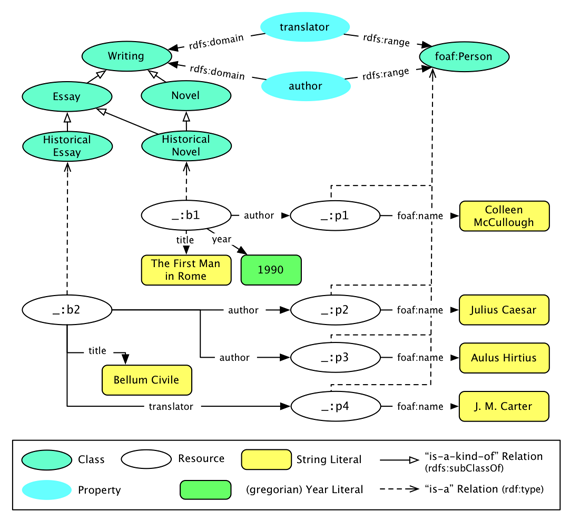
@prefix foaf: <http://xmlns.org/foaf/0.1/> .
:Writing a rdfs:Class ; rdfs:label "Novel" .
:Novel a rdfs:Class ; rdfs:label "Novel" ;
rdfs:subClassOf :Writing .
:Essay a rdfs:Class ; rdfs:label "Essay" ;
rdfs:subClassOf :Writing .
:Historical_Essay a rdfs:Class ;
rdfs:label "Historical Essay"; rdfs:subClassOf :Essay.
:Historical_Novel a rdfs:Class ;
rdfs:label "Historical Novel" ;
rdfs:subClassOf :Novel ; rdfs:subClassOf :Essay .
:author a rdf:Property ;
rdfs:domain :Writing ; rdfs:range foaf:Person .
:translator a rdf:Property ;
rdfs:domain :Writing ; rdfs:range foaf:Person .
_:b1 a :Historical_Novel ;
:title "The First Man in Rome" ;
:year "1990"^^xsd:gYear ;
:author [foaf:name "Colleen McCullough"] .
_:b2 a :Historical_Essay ;
:title "Bellum Civile" ;
:author [foaf:name "Julius Caesar"] ;
:author [foaf:name "Aulus Hirtius"] ;
:translator [foaf:name "J. M. Carter"] .
Query 1: “Select all essays together with their authors (i.e., author items and corresponding names)”
Query 2: “Select all data items with any relation to the book titled ‘Bellum Civile’.”
Query 3: “Select all data items except ontology information and translators from the book recommender system.”
Query 4: “Invert the relation author (from a book to an author) into a relation authored (from an author to a book).”
Julius Caesar is author of
Bellum Civile becomes
_:1 a rdf:Statement . _:1 rdf:subject Julius Caesar . _:1 rdf:predicate author . _:1 rdf:object Bellum Civile .
Query 5: “Return the last year in which an author with name ‘Julius Caesar’ published something.”
max(·) aggregationcount(·)
Query 6: “Return each of the subclasses of ‘Writing’, together with the average number of authors per publication of that subclass.”
Query 7: “Combine the information about the book titled
‘The Civil War’ and authored by
‘Julius Caesar’ with the
information about the book with identifier
bellum_civile.”
Query 9: “Return theco-authorrelation between two persons that stand inauthorrelationships with the same book.”
Query 8: “Return the transitive closure of the
subClassOf relation.”
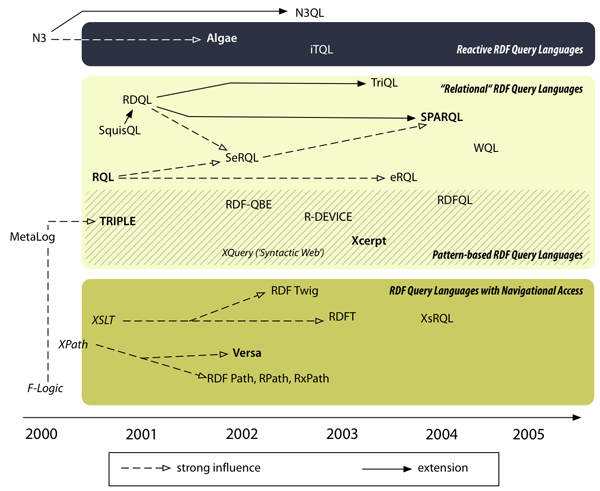
Figure 2: Chronological Overview of RDF Query Languages
WHERE clauseSELECT defines the answer variables of the
queryCONSTRUCT allows alternatively to specify a
graph pattern that is instantiated against
variable bindings
PREFIX books: <http://example.org/books#>
SELECT ?essay ?author ?authorName
FROM <http://example.org/books>
WHERE { ?essay rdf:type books:Essay .
?essay books:author ?author .
?author books:name ?authorName . }
;),)? or
$ prefixSELECT clause specifies list of answer variablesCONSTRUCT specifies graph pattern
instantiated against answer variable bindingsFROM specifies the URL(s) of the data graph(s) to be queriedWHERE specifies the graph patternFILTER ClauseFILTER contains conditional
expression over query variablesWHERE, but
=, <, ...)
PREFIX books: <http://example.org/books#>
SELECT ?person
FROM <http://example.org/books>
WHERE { ?book books:author ?person .
?book books:title ?title .
FILTER (?title = 'Bellum Civile') }
:= reported in answer if present, but
presence not required
What is the meaning to the following query?
SELECT ?writing ?translator ?translator-name
FROM <http://example.org/books>
WHERE { ?writing books:author _:Author .
OPTIONAL { ?writing books:translator ?translator } .
OPTIONAL { ?translator foaf:name ?translator-name } .
OPTIONAL B
is a solution of either A ∧ B or of A
∧ ¬B “Find me all writings that have an
author and return also their translator and its name if they
have an translator. If they have no translator, return all pairs
of subjects and objects in a triple with predicate
foaf:name.”
OPTIONAL uses negatioOPTIONAL to
implement the otherwise missing negation in SPARQL
PREFIX books: <http://example.org/books#>
SELECT ?writing
FROM <http://example.org/books>
WHERE { ?writing books:author _:Author .
OPTIONAL { ?writing books:translator ?translator } .
FILTER (!bound(?translator)) }
“Return all resources with an author that have no
translator”, on which optional triple yields no
?translator bindings
UNION, OPTIONAL
can not be rewritten to a UNION
as common from SQL or XQuery due to the lack of negation as
first-class conceptCONSTRUCT clause specifies graph
template (syntactically like graph pattern)
CONSTRUCT must also occur in remainder of
query
CONSTRUCT {?x books:co-author ?y}
FROM <http://example.org/books>
WHERE { ?book books:author ?x .
?book books:author ?y .
FILTER (?x != ?y) }
PREFIX books: <http://example.org/books#>
SELECT ?essay ?property ?propertyValue
FROM <http://example.org/books>
WHERE {?essay books:title "Bellum Civile" .
OPTIONAL { ?essay ?property ?propertyValue } }
DESCRIBE: specialized form of extraction query
:= access to
multiple graphs at the same SPARQL "endpoint"WHERE clause using
GRAPH keywordFROM clauses)FROM
NAMED clauses) FILTER clauses using
OPTIONAL variablesrdfs:Class
SELECT X, Y FROM {X;books:Essay}books:author.books:authorName{Y},
{X}books:title{T}
WHERE T = "Bellum Civile"
USING NAMESPACE books = &http://example.org/books#
FROM contains triple patterns, no
literalsWHERE additional conditions
(FILTER in SPARQL) including literal
restrictionssubClassOf(books:Writing) retrieves
sub-classes of
books:Writingtopclass(books:Historical_Essay)
returns top-level of subsumption hierarchySELECT X, Y FROM Class{X},
subClassOf(X){Y} for Query 8author property
SELECT $C1, $C2 FROM {$C1}books:author{$C2}
SELECT C1, C2 FROM Class{C1}, Class{C2}, {;C1}books:author{;C2}
SELECT C1, C2 FROM subClassOf(domain(book:author)){C1},
subClassOf(range(books:author)){C2}
SELECT X, Y, Z FROM {X;books:Essay}books:author{Y}.books:authorName{Z}
USING NAMESPACE books = &http://example.org/books#
{X;books:Essay} limits bindings for
X to type books:EssayWHERE clauses (even
for basic literals)
SELECT X, Y FROM {X;books:Essay}books:author.books:authorName{Y},
{X}books:title{T}
WHERE T = "Bellum Civile"
USING NAMESPACE books = &http://example.org/books#
books:Writing{X} and
properties books:author
^, e.g., ^books:Writing{X}
SELECT $C, ( SELECT @P, Y FROM {Z ; ^$D} ^@P {Y}
WHERE Z = X and $D = $C )
FROM ^$C {X}, {X}books:title{T} WHERE T = "Bellum Civile"
USING NAMESPACE books = &http://example.org/books#
@
SELECT @P, $V FROM {;books:Writing}@P{$V}
USING NAMESPACE books = &http://example.org/books#
SELECT S, @P, O
FROM (Resources minus (SELECT T FROM {B}books:translator{T})){S},
(Resources minus (SELECT T FROM {B}books:translator{T})){O},
{S}@P{O}
max(SELECT Y
FROM {B;books:Writing}books:author.books:authorName{A},
{B}books:pubYear{Y}
WHERE A = "Julius Caesar")
CREATE NAMESPACE mybooks = &http://example.org/books-rdfs-extension#
VIEW mybooks:co-author(A1, A2)
FROM {Z}books:author{A1}, {Z}books:author{A2} WHERE A1 != A2
<·>):
Julius_Caesar[believes
→<Junius_Brutus[friend-of → Julius_Caesar]>]
rdf := 'http://www.w3.org/1999/02/22-rdf-syntax-ns#'.
books := 'http://example.org/books#'.
FORALL B, A, AN result(B, A, AN) ←
B[rdf:type → books:Essay;
books:author → A[books:authorName -> AN]]@'http://example.org/books'.
rdf := 'http://www.w3.org/1999/02/22-rdf-syntax-ns#'.
rdfs := 'http://www.w3.org/2000/01/rdf-schema#'.
FORALL Mdl @rdfschema(Mdl) {
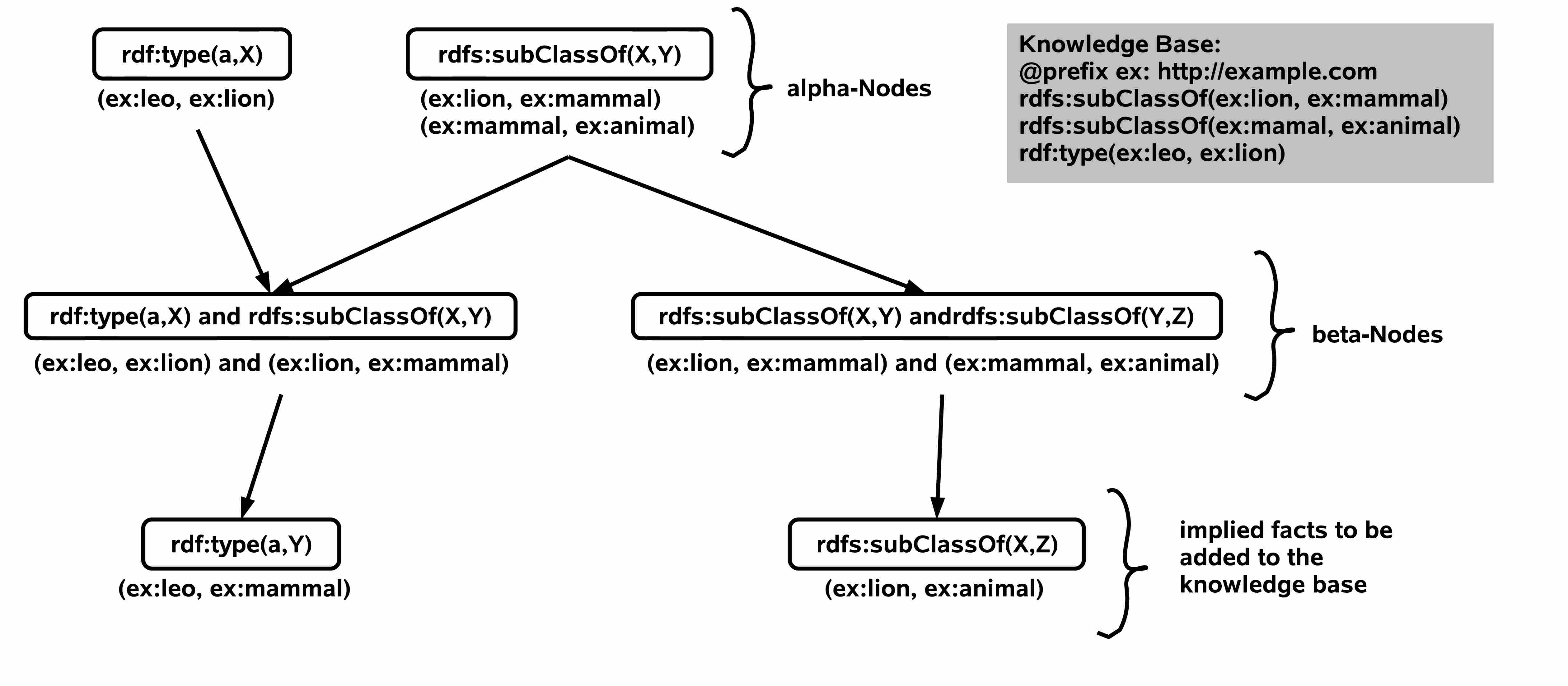
transitive(subPropertyOf). transitive(subClassOf).
FORALL O,P,V O[P→V] ← O[P→V]@Mdl.
FORALL O,P,V O[P→V] ←
EXISTS S S[rdfs:subPropertyOf→P] AND O[S→V].
FORALL O,P,V O[P→V] ←
transitive(P) AND EXISTS W (O[P→W] AND W[P→V]).
FORALL O,T O[rdf:type→T] ←
EXISTS S (S[rdfs:subClassOf→T] AND O[rdf:type→S]). }
FORALL S,T S[type→T] ←
EXISTS P, O (S[P→O] AND P[rdfs:domain→T]).
FORALL O,T O[type→T] ←
EXISTS P, S (S[P→O] AND P[rdfs:range→T]).
optional
construct
GOAL
result [
all essay [
id [ var Essay ],
all author [
id [ var Author ], all name [ var AuthorName ]
] ] ]
FROM
and(
RDFS-TRIPLE [ var Essay, rdf:type, books:Essay ],
RDF-TRIPLE [ var Essay, books:author, var Author ],
RDF-TRIPLE [ var Author, books:authorName, var AuthorName ] )
END
RDFS-TRIPLE instead of RDF-TRIPLE:
use of view over RDF/S entailment graph
GOAL
result [
all essay [
id [ var Essay ],
all author [
id [ var Author ], all name [ var AuthorName ]
] ] ]
FROM
RDFS-GRAPH {{
var Essay {{
rdf:type {{ books:Essay }},
books:author {{
var Author {{
books:name {{ var AuthorName }} }}
}} }} }}
END
CONSTRUCT
RDF-TRIPLE[ var Subject, var Predicate:uri{}, var Object ]
FROM
and[
rxr:graph {{
rxr:triple {
var S as rxr:subject{{}},
rxr:predicate{ attributes{ rxr:uri{ var Predicate } } },
var O as rxr:object{{}}
}
}},
rxr:NODE2URI[ var S, var Subject ], rxr:NODE2URI[ var O, var Object ] ]
END
NODE2URI maps different resource
representations to URIs
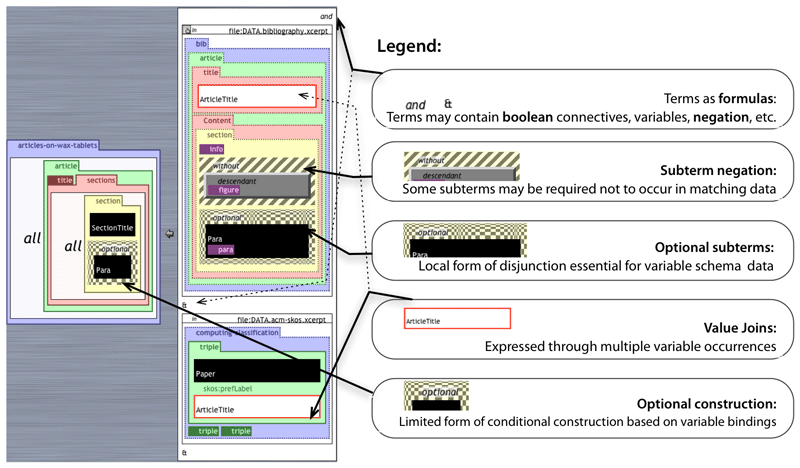
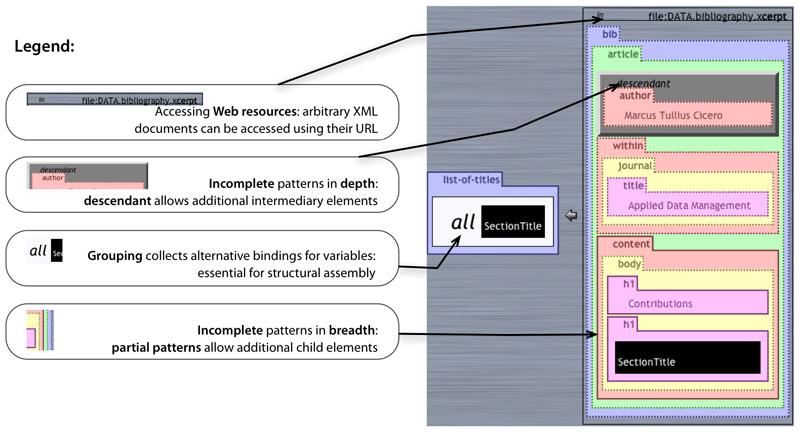
OPTIONAL as in SPARQL but with stronger
semantics ask,
assert, and fwrule for querying,
insertion, and ECA rules
ask (?essay books:year ?year {?year >= 62 && ?year < 301} .)
read <http://example.org/books> ()
ask ( ?essay rdf:type <http://example.org/books#Essay> .
?essay books:author ?author .
?author books:authorName ?authorName )
collect( ?essay, ?author, ?authorName )
~ used to declare `translator' triple
optional
ask ( ?essay rdf:type <http://example.org/books#Essay> .
?essay books:author ?author .
?author books:authorName ``Julius Caesar'' .
?essay books:title ?title .
~?essay books:translator ?translator . )
collect( ?title, ?translator )
?title |
?translator |
Proof |
|---|---|---|
| "Bellum Civile" | "J. M. Carter" |
_:1 rdf:type <http://exam...ks-rdfs#Essay>. _:1 books:author _:2. _:2 books:authorName ``Julius Caesar''. _:1 books:title ``Bellum Civile''. _:1 books:translator ``J. M. Carter''. |
all() - books:author -> *
all(), type()all() <- rdf:type - *traverse traverse in specified direction even transitively, e.g.,
traverse(books:Writing, rdf:subClassOf, vtrav:inverse, vtrav:transitive)
type(books:Essay) |-books:title-> eq("Bellum
Civile") selects essaystype(books:Essay) -books:title-> eq("Bellum
Civile") selects title literalsdistribute()
distribute(type(books:Essay), ".", "distribute(.-books:author->*, ".", ".-books:authorName->*)")
. indicates the context nodefilter()
filter(books:Essay <- rdf:type - *,
". - books:title -> eq('Bellum Gallicum')",
". - books:translator -> books:translatorName -> eq('J. M. Carter')"
max(filter(all(),
". - books:author -> books:authorName -> eq('Julius Caesar')" )
- books:year -> *)
distribute(traverse(books:Writing, rdf:subClassOf,
vtrav:inverse,vtrav:transitive),
".",
"avg(length((. <- rdf:type *) - books:author -> *))" )
map,
filter)
difference(all(),
union(type(rdfs:Class),
union(type(rdf:Property,
all() <- books:translator - *) ) ) )
:= ability to
characterize
?essay books:title "Bellum Civile"
?essay books:author ?author. ?author foaf:name "Julius Caesar"
?essay books:author [ foaf:name "Julius Caesar" ].
{Essay}books:author.foaf:name{A}.
a*.((b|c).e)+ traverses all paths of
desc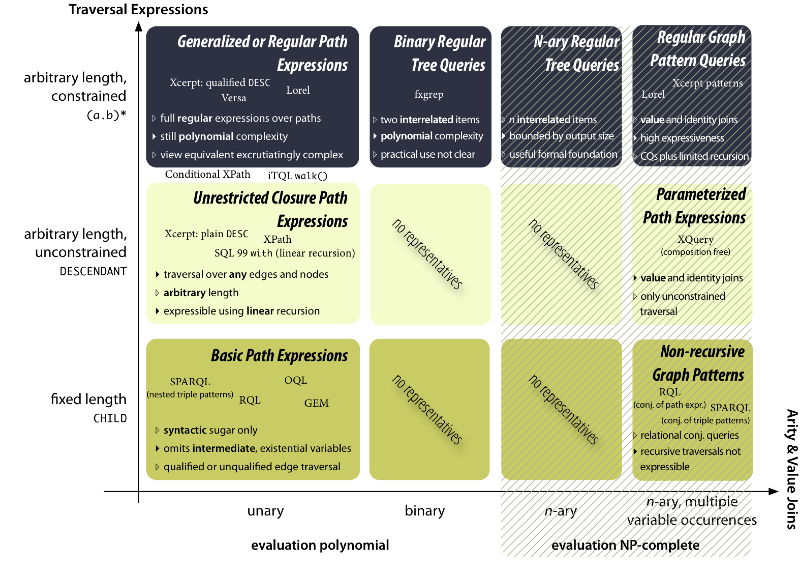
DESCRIBE
SELECT ?writing, ?translator
WHERE { ?writing a books:Essay .
OPTIONAL { ?writing books:translator ?translator } }
SELECT ?writing, ?translator
WHERE { ?writing a books:Essay .
?writing books:translator ?translator }
UNION
{ ?writing a books:Essay }
Slight difference in semantics: books with at least one
translator are still reported also once with empty binding for
?translator
A ∧ optional B ∧
optional C
The following query selects essays together with translators and, if that translator is also an author, also the author name.
SELECT ?writing, ?person, ?name
WHERE { ?writing a books:Essay .
OPTIONAL { ?writing books:translator ?person }
OPTIONAL { ?writing books:author ?person .
?person foaf:name ?name } }
Switching order of the optionals changes
semantics → second optional superfluous
Select all essays together with authors and author names (if
there are any).
SELECT ?writing, ?person, ?name
WHERE { ?writing a books:Essay .
OPTIONAL { ?writing books:translator ?person
OPTIONAL { ?writing books:author ?person .
?person foaf:name ?name }
} }
UNION can be used to express OPTIONAL
SELECT ?writing, ?translator
WHERE { ?writing a books:Essay .
?writing books:translator ?translator }
UNION
{ ?writing a books:Essay }
?translator
even if a translator existsoptional B ∧
optional C equivalent to
Sequence container ⟨A, B, C⟩ is reduced to:
_:1 rdf:type rdf:Sequence _:1 rdf:_1 A _:1 rdf:_2 B _:1 rdf:_3 C
Similarly, collections are reduced to binary relations of
rdf:first and rdf:last:
_:1 rdf:first A _:1 rdf:rest _:2 _:2 rdf:first B _:2 rdf:rest _:3 _:3 rdf:first C _:3 rdf:rest rdf:nil
rdf:first.(rdf:rest.rdf:first)*
SELECT ?contained_resource
WHERE { ?C ?P ?contained_resource .
FILTER(regex(str(?P),
"http://www.w3.org/1999/02/22-rdf-syntax-ns#_\d+")) }
R
in C to test membership of resource R in
container C
SELECT R, count(SELECT @P FROM {R @P }
FROM {R}books:author{A}
WHERE A = "Julius Caesar"
The basic form of graph construction in SPARQL is
CONSTRUCT { ?R ?P ?O }
WHERE { ?R books:author "Julius Caesar". ?R ?P ?O }
UNION over full
queries (Algae, Xcerpt, Triple)if ... then ... or
case constructs?P
rdf:type my:Teen for persons with ?Age between 12
and 18 and the triple ?P rdf:type my:Adult for
older persons.Methods for RDF query evaluation differ in several aspects:
(s,p,o,c) of subject,
predicate, object and so-called context information
(?X, foaf:knows, ?Y)),
versus conjunctive queriesFocus of this article: non-distributed evaluation of conjunctive queries on triple/quadruple stores on disks.
According to the directory of the Free Software Foundation14, the Berkeley Database is
Usage of Berkeley DB in RDF storage
| subject | predicate | object |
|---|---|---|
| http://example.com#subj1 | http://example.com#pred1 | "an example literal" |
| ... | ... | ... |
|
|
| Subject | foaf:homepage | foaf:nick | ... |
|---|---|---|---|
| http://example.com#Miller | http://miller.com/index.html | "Milli" | ... |
| ... | ... | ... | ... |
C-library developed at the University of SouthamptonStatements table:
| model (int64) | subject (int64) | predicate (int64) | object (int64) | literal (boolean) | inferred (boolean) |
Model-, URI- and Literals-table:
|
|
|
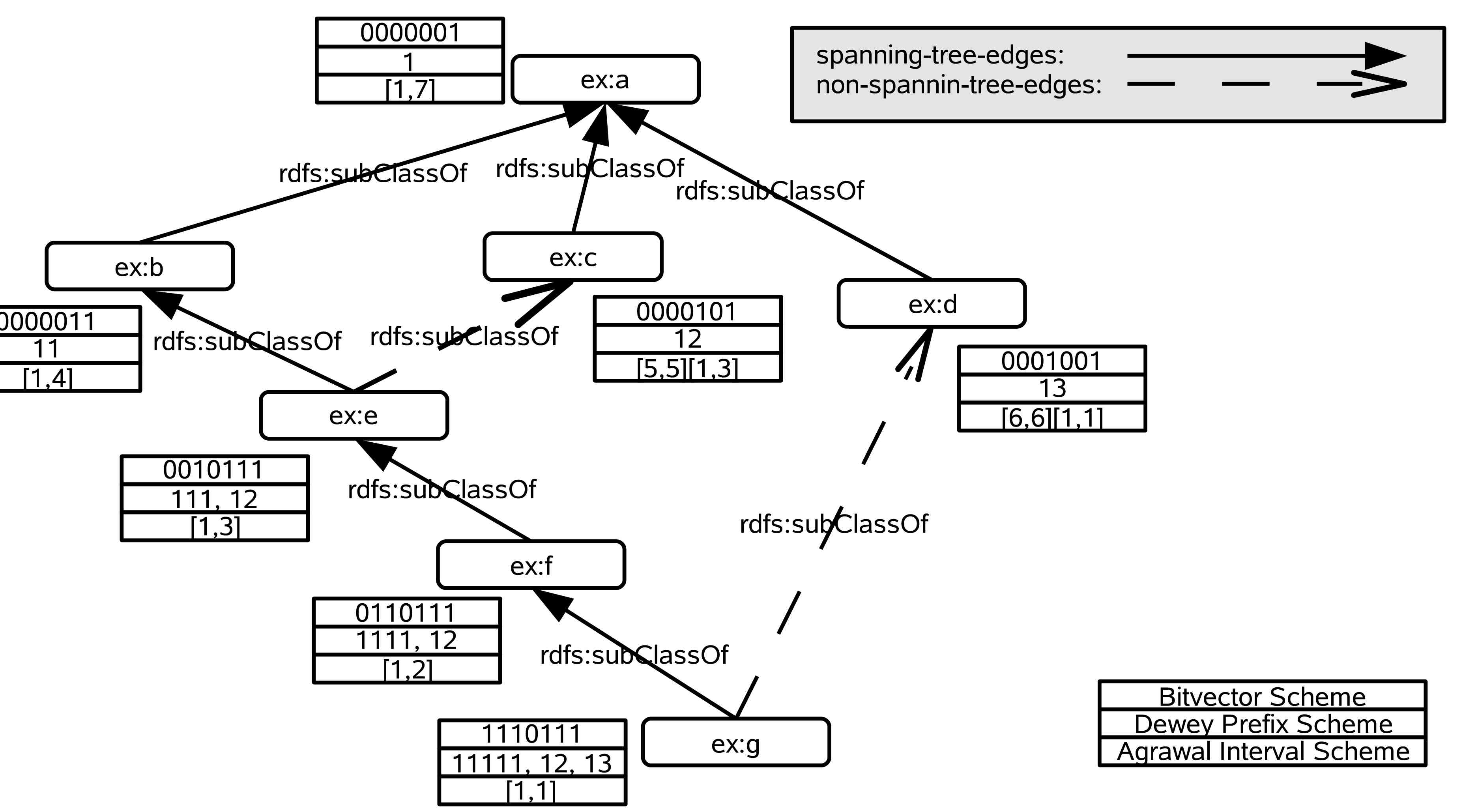
rdfs:subClassOf-predicates.rdf:type,
rdfs:subClassOf, rdfs:subPropertyOfsubProperty, subClass, Class,
Type
(v0,v1),
(v1,v2), ...,
(vk-1,vk)
#title<#sculpts for two triples with predicates
title and sculpts.
|
|
p1, ..., pmpi, 1 <= i <= m is the position of the
ith suffix (in lexicographical order) in M.(pa1,po1), ...,
(pal,pol)
pai: path number of the ith suffix
(in lexicographical order)poi: position of the ith suffix within
paiOID → StringString → OID→ OIDs
|
|
T. Furche, B. Linse, F. Bry, D. Plexousakis, and G. Gottlob: “RDF Querying: Language Constructs and Evaluation Methods Compared”. In: Reasoning Web, Second International Summer School 2006, P. Barahona et al., (Eds.) Springer-Verlag, LNCS 4126, pp. 1–52, 2006. © Springer-Verlag Berlin Heidelberg 2006
This research has been funded by the European Commission and by the Swiss Federal Office for Education and Science within the 6th Framework Programme project REWERSE number 506779 (cf. http://rewerse.net).
All references can be found in the article
Tim Furche, Benedikt Linse, François Bry, Dimitris Plexousakis, and Georg Gottlob:
"RDF Querying: Language Constructs and Evaluation Methods Compared".
In: Reasoning Web, Second International Summer School 2006, P. Barahona et al., (Eds.) Springer-Verlag, LNCS 4126, pp. 1–52, 2006.
© Springer-Verlag Berlin Heidelberg 2006

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 2.0 License.